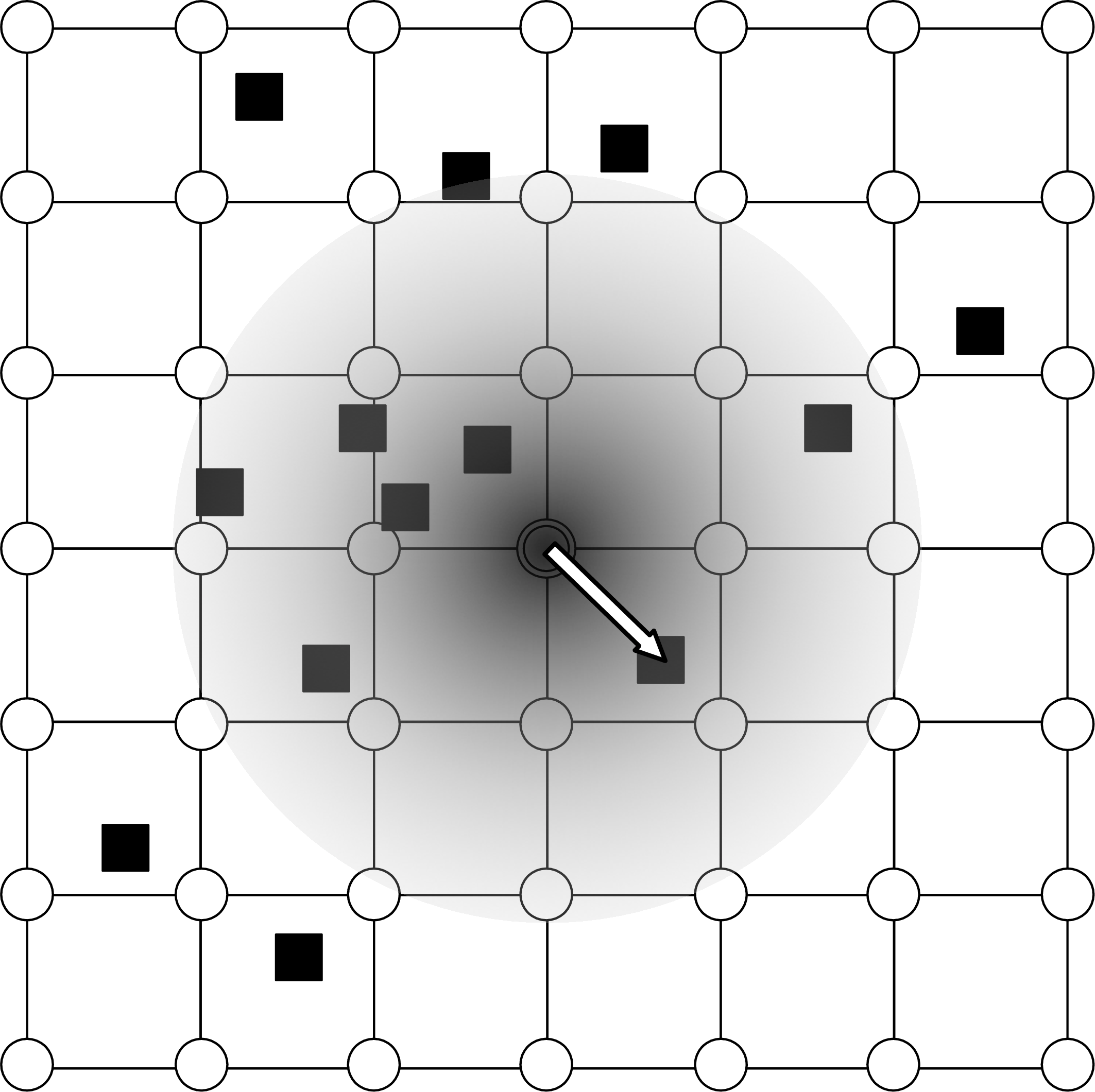
観測データは初期値の格子上で取得されたとは限らず、取得された時刻も様々で、観測される変数、観測点の分布、測器の精度も多様である。 数値天気予報(numerical weather prediction)の初期値としては、規則的な格子上のデータが必要である Figure 1.1。 観測データ(observation)を数値予報モデルに取り込むことをデータ同化(data assimilation)という。 客観的な一定の方法に従って、最適(optimal)な場を推定したものを客観解析(objective analysis)という。
線型回帰
回帰分析(regression analysis)は、二つの変数の\(x\)と\(y\)のデータが与えられたときに、\(y=f(x)\)というモデルを当てはめる。 \(x\)を説明変数、\(y\)を目的変数と呼び、\(x\)がスカラーの場合を単回帰(simple regression)、ベクトルの場合を重回帰(multiple regression)という。 モデルが線型\(f(x) = \beta_0 + \beta_1 x\)なら、線型回帰、\(f(x)=ax^b, f(x)=ae^{bx}, f(x)=a + b\log x\)のように非線型なら非線型回帰という。 様々な当てはめ(curve-fitting)がある。
\(n\)個の観測\(y_1, \dots, y_n\)が与えられたとき、線型モデルでは次のように書ける。
\[
y_i = \beta_0 + \beta_1 x_i + \varepsilon_i
\tag{1.1}\]
\(\varepsilon_i\)は誤差を表している。 最小分散推定(minimum variance)は最小二乗法(method of least squares)とも呼ばれ、誤差の分散
\[S=\sum_i \varepsilon_i^2 \tag{1.2}\] を最小にする\(\beta_0,\,\beta_1\)を求める。
Equation 1.2を\(\beta_0,\,\beta_1\)で微分して0と置くと、正規方程式
\[
\begin{aligned}
\frac{\partial S}{\partial \beta_0} &= -2\sum[y_i - (\beta_0 + \beta_1 x_i)] = 0\\
\frac{\partial S}{\partial \beta_1} &= -2\sum[y_i - (\beta_0 + \beta_1 x_i)]x_i = 0
\end{aligned}
\tag{1.3}\]
平均
\[
\bar{x} = \frac{1}{n}\sum{x_i},\;\bar{y} = \frac{1}{n}\sum{y_i}
\] を用いると、Equation 1.3 の最初の式から
\[
\bar{y} = \beta_0 + \beta_1\bar{x}
\tag{1.4}\]
が得られる。 \[
\begin{aligned}
\sum (x_i-\bar{x})\bar{x} &= \bar{x}\sum{x_i} - n\bar{x} = 0\\
\sum (y_i-\bar{y})\bar{x} &= \bar{x}\sum{y_i} - n\bar{x}\bar{y} = 0
\end{aligned}
\] を用いると \[
\begin{aligned}
\hat{\beta}_0 &= \bar{y} - \beta_1\bar{x}\\
\hat{\beta}_1 & = \frac{\sum(x_i-\bar{x})(y_i-\bar{y})}{\sum(x_i-\bar{x})^2} = \frac{\mathrm{cov}(x,\,y)}{\mathrm{var}(x)}
\end{aligned}
\] を得る。 \(\hat{\beta}_1\)を回帰係数という。
例1 予報と観測
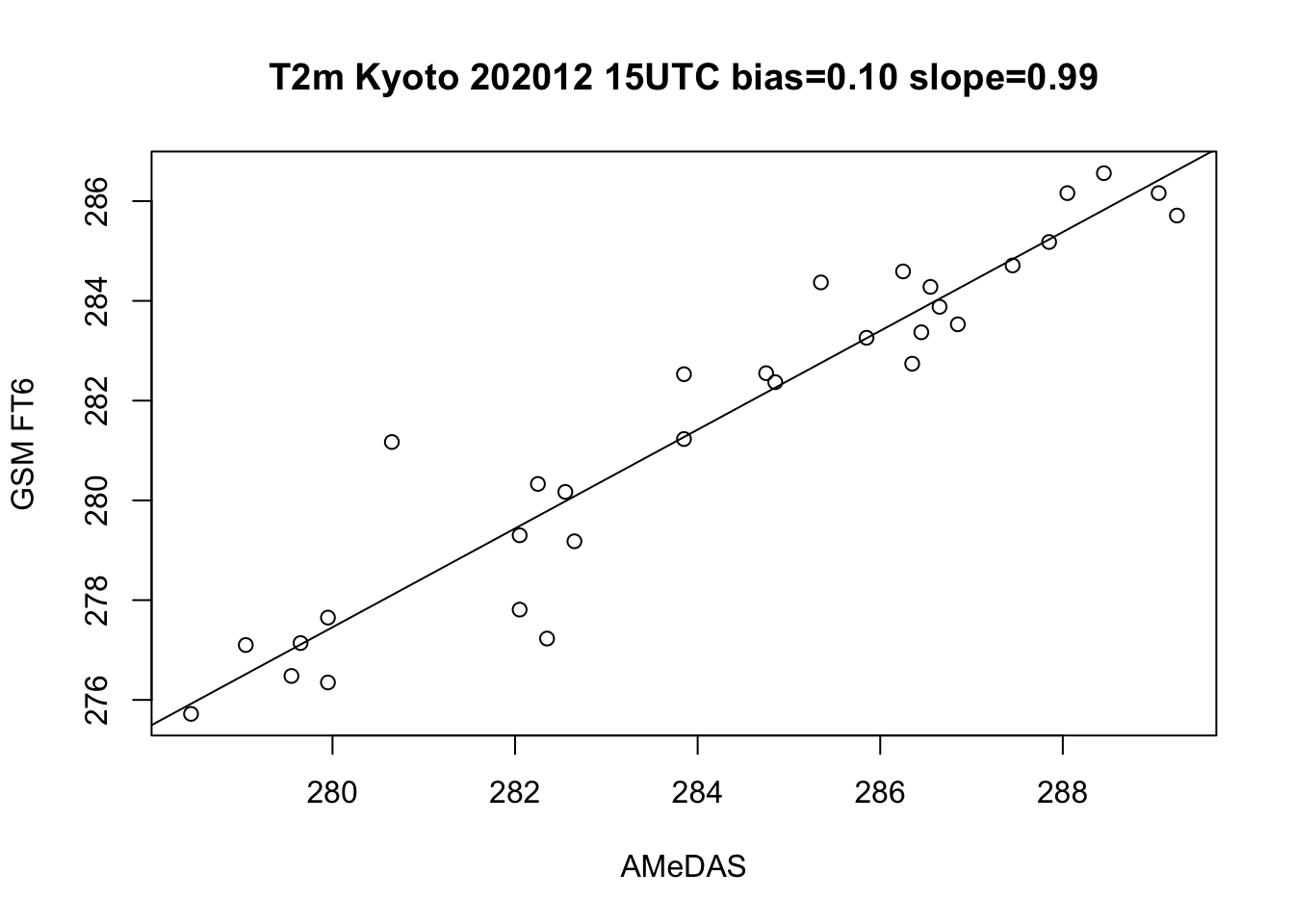
2020年12月の気象庁GSMの0000 UTCから6時間予報と京都のアメダスで観測された気温と風速を比較する。
まず、平均を計算し、分散、共分散から、傾きと切片を計算する。
Code
t2.o <- scan("data/amedas_kyoto_t2_20201206.txt") + 273.15
t2.f <- scan("data/gsm_ft6_t2m_202012.txt")
mean.x <- mean(t2.o)
var.x <- var(t2.o)
mean.y <- mean(t2.f)
cov.xy <- cov(t2.o, t2.f)
beta1 <- cov.xy / var.x
beta0 <- mean.y - beta1 * mean.x
cat("mean.x=", mean.x, " var.x=", var.x, " mean.y=", mean.y, " cov.xy=", cov.xy, "\n")
mean.x= 284.1565 var.x= 10.51396 mean.y= 281.5745 cov.xy= 10.4146
Code
cat("beta0 =", beta0, " beta1=", beta1, "\n")
beta0 = 0.1032584 beta1= 0.9905503
散布図を描いてみると、非常に対応が良いことが分かる。
Code
lm.t2 <- lm(t2.f ~ t2.o)
plot(t2.o, t2.f, xlab="AMeDAS", ylab="GSM FT6",
main=paste0("T2m Kyoto 202012 15UTC bias=",
sprintf("%0.2f", lm.t2$coefficients[1]),
" slope=", sprintf("%0.2f", lm.t2$coefficients[2])))
abline(lm.t2)
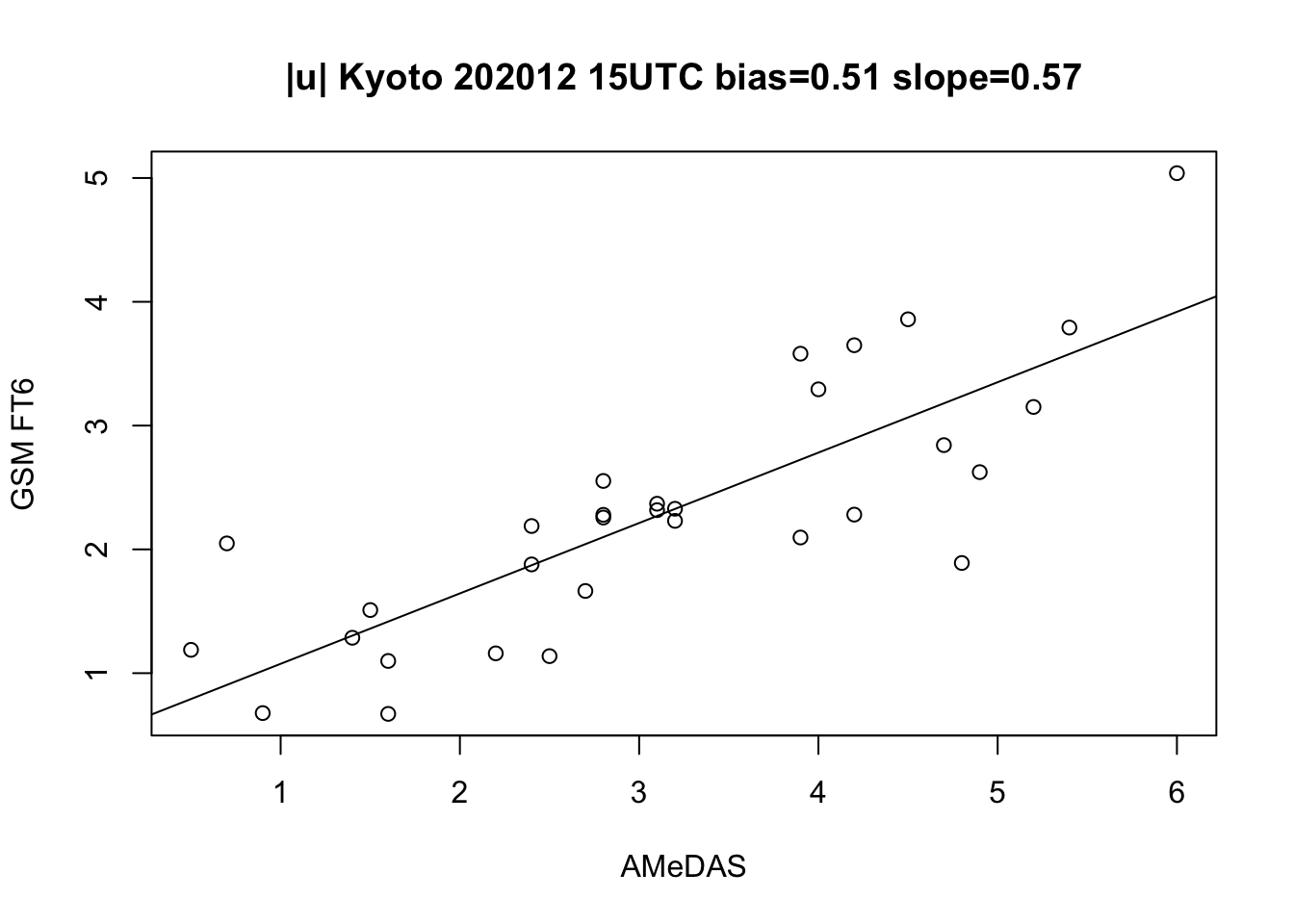
次に10 m風速と京都のアメダスで観測された風速を比較する。 予報は観測される強い風を表現しておらず、回帰直線の傾きが小さい。
Code
lm.ws <- lm(ws.f ~ ws.o)
plot(ws.o, ws.f, xlab="AMeDAS", ylab="GSM FT6",
main=paste0("|u| Kyoto 202012 15UTC bias=",
sprintf("%0.2f", lm.ws$coefficients[1]),
" slope=", sprintf("%0.2f", lm.ws$coefficients[2])))
abline(lm.ws)
ガウス分布
平均\(\bar{x}\)、標準偏差\(\sigma\)の正規分布は
\[
P(x) = \frac{1}{\sqrt{2\pi}\sigma}\exp\left\{-\frac{(x-\bar{x})^2}{2\sigma^2}\right\}
\tag{1.5}\]
\(n\)次元のベクトル\(\mathbf{x}\)に対しては \[
P(\mathbf{x}) = \frac{1}{(2\pi)^{n/2}|\mathbf{S}_x|^{1/2}}\exp\left\{
-(\mathbf{x}-\bar{\mathbf{x}})^\mathrm{T}\mathbf{S}_x^{-1}(\mathbf{x}-\bar{\mathbf{x}})\right\}
\tag{1.6}\] と書ける。 ここで\(\mathbf{S}_x\)は共分散行列である。
Code
curve(dnorm, xlim=c(-5, 5))
ベイズの定理
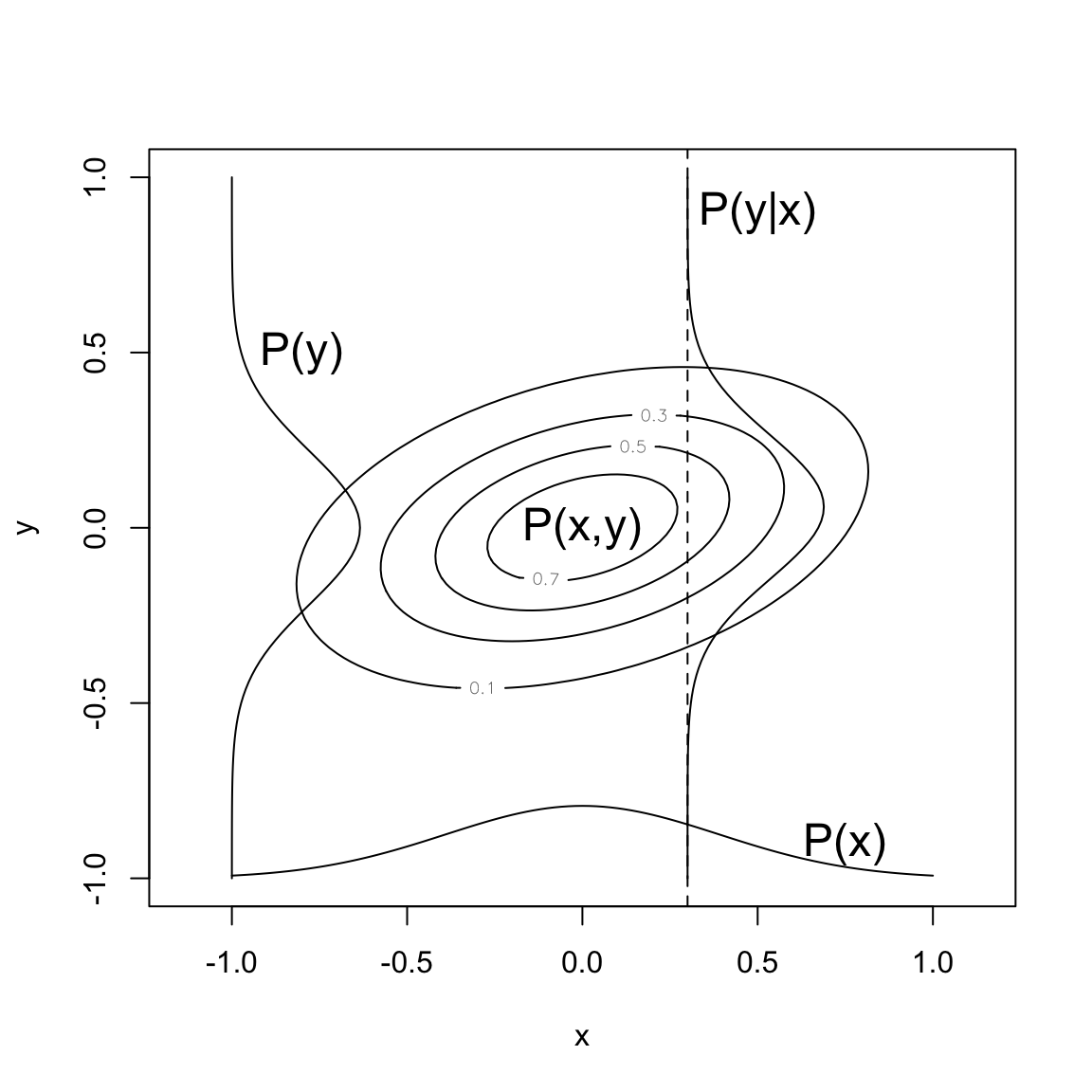
Rodgers (2000) に基づいて、状態\(\mathbf{x}\)と観測\(\mathbf{y}\)がスカラーの場合について、同時確率密度分布(pdf: probability distribution function)の例を図示する。
Code
gaussian2d <- function(x, y, a, b, theta) {
sdev <- sqrt(a^2 + b^2)
theta <- theta * pi / 360
pmat <- matrix(c(cos(theta), -sin(theta), sin(theta), cos(theta)), nrow=2)
smat <- diag(c(1/a^2, 1/ b^2))
sinv <- as.vector(t(pmat) %*% smat %*% pmat)
1 / (sqrt(2 * pi) * sdev) *
exp(-0.5 * (sinv[1] * x^2 + (sinv[2]+sinv[3]) * x * y + sinv[4] * y^2))
}
a <- 0.4
b <- 0.2
theta <- 30
x1 <- 0.3
x <- seq(-1, 1, length=101)
y <- x
pdf <- outer(x, y, gaussian2d, a, b, theta)
px <- rowMeans(pdf)
px <- px / sum(px)
py <- colMeans(pdf)
py <- py / sum(py)
pyx <- pdf[which.min(abs(x - x1)),]
pyx <- pyx / sum(pyx)
clev <- c(0.1, 0.3, 0.5, 0.7)
contour(x, y, pdf, xlab="x", ylab="y", levels=clev, asp=1)
lines(x, 10 * px - 1.0, type="l")
lines(10 * py - 1.0, y, type="l")
abline(v = x1, lty=2)
lines(10 * pyx + x1, y, type="l")
text(0.0, 0.0, "P(x,y)", cex=1.5)
text(0.75, -0.9, "P(x)", cex=1.5)
text(0.5, 0.9, "P(y|x)", cex=1.5)
text(-0.8, 0.5, "P(y)", cex=1.5)
- \(P(\mathbf{x})\): 状態\(\mathbf{x}\)のpdf。\(P(\mathbf{x})\mathrm{d}\mathbf{x}\)は、測定をする前に多次元体積\((\mathbf{x}, \mathbf{x}+\mathrm{d}\mathbf{x})\)に\(\mathbf{x}\)が存在する確率。 測する前において\(\mathbf{x}\)について分かっている。\(\int P(\mathbf{x})\mathrm{d}\mathbf{x}=1\)となるように規格化される。
- \(P(\mathbf{y})\): 測定の先験pdf。測定前の測定のpdfを表す。
- \(P(\mathbf{x},\mathbf{y})\): \(\mathbf{x}\)と\(\mathbf{y}\)との同時先験pdf。\(P(\mathbf{x},\mathbf{y})\mathrm{d}\mathbf{x}\mathrm{d}\mathbf{y}\)は、\(\mathbf{x}\)が\((\mathbf{x},\mathbf{x}+\mathrm{d}\mathbf{x})\)に存在し かつ\(\mathbf{y}\)が\((\mathbf{y},\mathbf{y}+\mathrm{d}\mathbf{y})\)に存在する確率。
- \(P(\mathbf{y}|\mathbf{x})\): \(\mathbf{x}\)が与えられたときの\(\mathbf{y}\)の条件付pdf。\(P(\mathbf{y}|\mathbf{x})\mathrm{d}\mathbf{x}\)は\(\mathbf{x}\)の値が与えられたとき\(\mathbf{y}\)が\((\mathbf{y},\mathbf{y}+\mathrm{d}\mathbf{y})\)に存在する確率。
- \(P(\mathbf{x}|\mathbf{y})\): \(\mathbf{y}\)が与えられたときの\(\mathbf{x}\)の条件付pdf。\(P(\mathbf{x}|\mathbf{y})\mathrm{d}\mathbf{x}\)は\(\mathbf{y}\)の値が与えられたとき\(\mathbf{x}\)が\((\mathbf{x},\mathbf{x}+\mathrm{d}\mathbf{x})\)に存在する確率。
Figure 1.2 において、\(P(y|x)\)は\(x\)に対する\(y\)の函数であり、\(\int P(y|x)\mathrm{d}y=1\)に規格化されるので、破線に沿った積分\(\int P(x,y)\mathrm{d}y = P(x)\)で同時分布\(P(x,y)\)を割ったものに等しい。 \[
P(y|x) = \frac{P(x, y)}{P(x)}
\tag{1.7}\]
\(P(x|y)\)についても同様に表し、Equation 1.7 を用いて\(P(x, y)\)を消去すると、ベイズの定理が得られる。 \[
P(x|y) = \frac{P(x, y)}{P(y)} = \frac{P(y|x)P(x)}{P(y)}
\tag{1.8}\] Equation 1.8 から\(P(x, y)\)をベクトルに拡張すると次のように書ける。 \[
P(\mathbf{x}|\mathbf{y}) = \frac{P(\mathbf{y}|\mathbf{x})P(\mathbf{x})}{P(\mathbf{y})}
\tag{1.9}\]
データ同化を含む逆問題では、\(P(\mathbf{x})\)及び\(P(\mathbf{y}|\mathbf{x})\)から\(P(\mathbf{x}|\mathbf{y})\)を推定する。 Equation 1.9 の分母はスケーリングの定数で、通常は無視できる。
最大後験推定
スカラーを一つ直接観測し
\[
y = x + \epsilon
\]
を得たとする。 \(x\)は第一推定値で分散は\(\sigma_\mathrm{f}^2\)、 \(\epsilon\)は観測誤差、観測の分散は\(\sigma_\mathrm{o}^2\)とする。 \(y\)の先験分散は \[\sigma_y^2 = \sigma_\mathrm{f}^2 + \sigma_\mathrm{o}^2 \tag{1.10}\] である。
\(P(y|x)\), \(P(x)\), \(P(y|x)\)がガウス分布(Equation 1.5)であるとすると、 \[
\begin{aligned}
-2\ln P(y|x) &= \frac{y-x}{\sigma_\mathrm{o}^2} + \mathrm{const} \\
-2\ln P(x) &= \frac{x-x^\mathrm{f}}{\sigma_\mathrm{f}^2} + \mathrm{const} \\
-2\ln P(x|y) &= \frac{x-x^\mathrm{a}}{\sigma_\mathrm{a}^2} + \mathrm{const}
\end{aligned}
\] と書ける。 Bayesの定理(Equation 1.9)を適用すると、\(x^2\)の係数から \[
\frac{1}{\sigma_\mathrm{a}^2} = \frac{1}{\sigma_\mathrm{o}^2} + \frac{1}{\sigma_\mathrm{f}^2}
\tag{1.11}\] を得る。 分散の逆数は精度の指標で、観測を第一推定値に同化することにより精度が向上することを示している。 Equation 1.11は \[
\sigma_\mathrm{a}^2 = \frac{\sigma_\mathrm{o}^2\sigma_\mathrm{f}^2}{\sigma_\mathrm{o}^2 + \sigma_\mathrm{f}^2}
\tag{1.12}\] と表すこともできる。 一方、\(x\)の係数から \[
\frac{x^\mathrm{a}}{\sigma_\mathrm{a}^2} = \frac{y}{\sigma_\mathrm{o}^2} + \frac{x^\mathrm{f}}{\sigma_\mathrm{f}^2}
\tag{1.13}\] Equation 1.13 は Equation 1.11 を用いて \[
x^\mathrm{a} = x^\mathrm{f} + \frac{\sigma_\mathrm{f}^2}{\sigma_\mathrm{o}^2 + \sigma_\mathrm{f}^2}(y-x^\mathrm{f})
\tag{1.14}\] と表すこともできる。 後験確率密度が最大になるような推定であるので、最大後験推定(MAP: Maximum a posteriori)と呼ばれている。 最尤推定(ML: maximum likelihood)推定と呼ばれることもあるが、尤度は\(P(\mathbf{y}|\mathbf{x})\)を指すので、厳密には先験情報がない場合にのみ、MAP推定とML推定が一致する。
簡単な例題
ここで考える例題は、2つの気温の測定値\(T_1, T_2\)から解析値\(T_\mathrm{a}\)を求める問題を考える。 真の値(truth)を\(T_\mathrm{t}\)とすると、測定値は
\[
\begin{aligned}
T_1 &= T_\mathrm{t}+\varepsilon_1 \\
T_2 &= T_\mathrm{t}+\varepsilon_2
\end{aligned}
\]
と書ける。 ここで\(\varepsilon_1,\varepsilon_2\)は誤差を表す。 真の値が分らないので、誤差(error)も分らない。 さらに、以下が仮定できるとする。
- バイアスがない。\(E(\varepsilon_1)=E(\varepsilon_2)=0\)。ここで, \(E(\ )\)は期待値を表す。
- 誤差の分散は既知。 \(E(\varepsilon_1^2)=\sigma_1^2, E(\varepsilon_2^2)=\sigma_2^2\)
- 誤差は無相関。\(E(\varepsilon_1\varepsilon_2) = 0\)
\[
T_\mathrm{a}=a_1T_1+a_2T_2
\tag{1.15}\]
- 解析誤差もバイアスがない。\(E(\varepsilon_\mathrm{a})=0\)とすると、\(a_1+a_2=1\)となる。
最小二乗法(method of least squares)では、平均二乗誤差が最も小さくなるようにする。 \[
\begin{aligned}
\sigma_\mathrm{a}^2 &= E[(T_\mathrm{a}-T_\mathrm{t})^2] \nonumber \\
&= a_1^2\sigma_1^2+(1-a_1)^2\sigma_2^2
\end{aligned}
\tag{1.16}\]
微分をとると \[
\frac{\partial \sigma_\mathrm{a}^2}{\partial a_1} = 2a_1\sigma_1^2 - 2(1-a_1)\sigma_2^2
\] となる。 最小値では微分が0になるので、 \[
a_1 = \frac{\sigma_2^2}{\sigma_1^2+\sigma_2^2},\; a_2=\frac{\sigma_1^2}{\sigma_1^2+\sigma_2^2}
\tag{1.17}\]
と求まる。 観測1の重みは、観測2の分散を分散の和で割ったものとして求まる。 分子分母に\(1/\sigma_1^2\sigma_2^2\)をかけると、
\[
a_1=\frac{1/\sigma_1^2}{1/\sigma_1^2+1/\sigma_2^2},\; a_2=\frac{1/\sigma_2^2}{1/\sigma_1^2+1/\sigma_2^2}
\tag{1.18}\]
とも書ける。 ばらつき(分散)が大きいほど小さくなるので、分散の逆数は精度を示す。 Equation 1.18 は、重みが精度に比例することを示す。 分散が小さいものに、より大きな重みをつけることになる。
Equation 1.16 に Equation 1.17 を代入して、解析値の分散を求めてみる。 \[
\begin{aligned}
\sigma_\mathrm{a}^2 &= \frac{\sigma_1^2\sigma_2^2}{\sigma_1^2+\sigma_2^2} \\
\frac{1}{\sigma_\mathrm{a}^2} &= \frac{1}{\sigma_1^2} + \frac{1}{\sigma_2^2}
\end{aligned}
\tag{1.19}\] Equation 1.19は、解析精度は全ての精度の和となる。
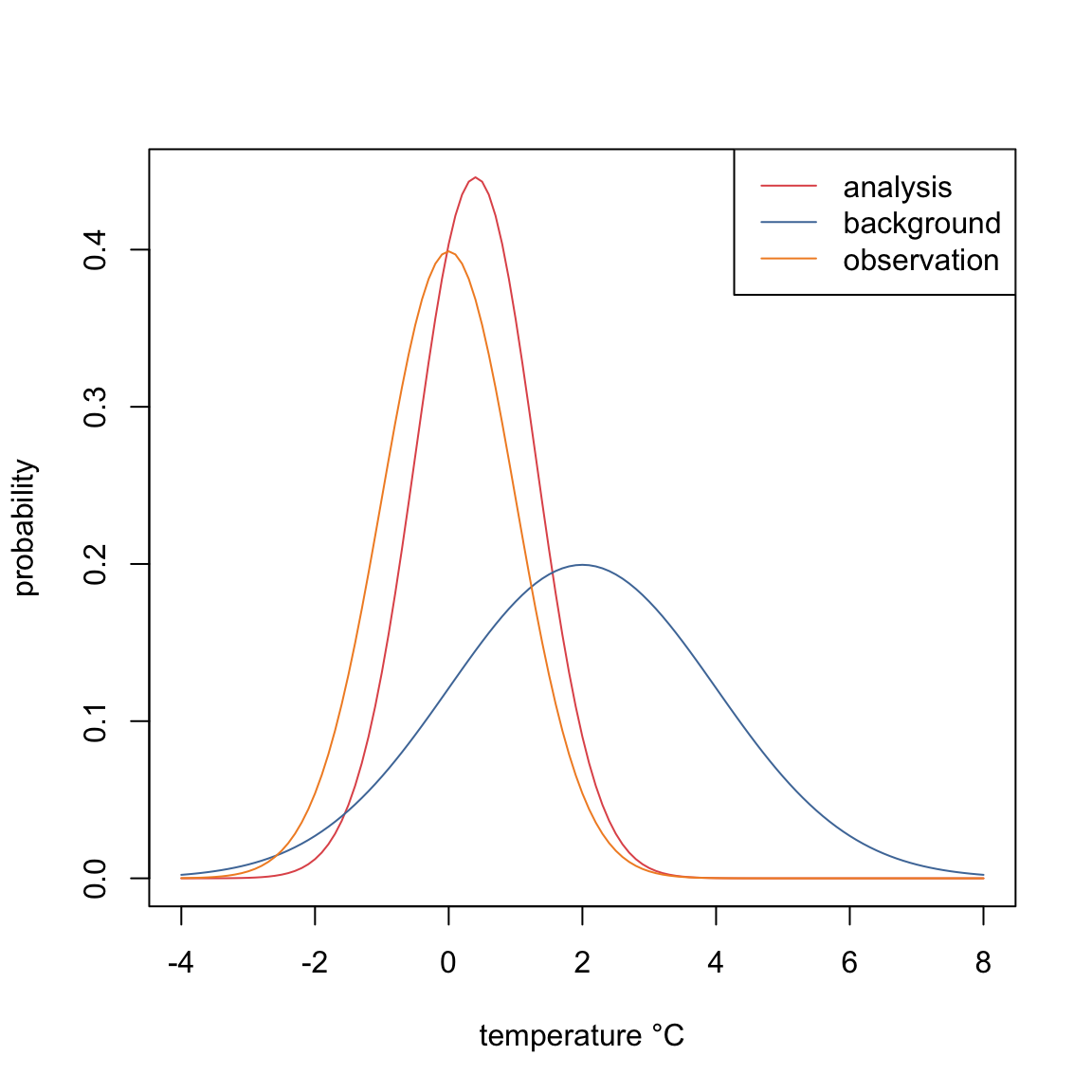
測定値1が第一推定値(\(T_1 = T_\mathrm{b}\))測定値2が観測値(\(T_2 = T_\mathrm{o}\))であるとする。 Equation 1.15は
\[
T_\mathrm{a} = T_\mathrm{b} + \frac{\sigma_\mathrm{b}^2}{\sigma_\mathrm{b}^2+\sigma_\mathrm{o}^2}(T_\mathrm{o} - T_\mathrm{b})
\tag{1.20}\]
と書くこともできる。 \(T_\mathrm{o} - T_\mathrm{b}\)をイノベーション(innovation)、右辺第二項を解析インクリメント(increment)と呼ぶ。 予測精度が悪い場合(\(\sigma_\mathrm{b}^2\)が大きい場合)や第一推定値が観測値からずれている場合(インクリメントが大きい場合)、Equation 1.20の第2項が大きくなり、観測に近くなるように修正される。
Code
xb <- 2.0
sb <- 2.0
xo <- 0.0
so <- 1.0
sa <- sqrt(1.0 / (1.0 / (sb * sb) + 1.0 / (so * so)))
xa <- xb + (sb*sb/(sb*sb + so*so)) * (xo - xb)
#print(xa)
#print(sa)
x <- seq(-4, 8, by=0.1)
yb <- dnorm(x, mean = xb, sd = sb)
yo <- dnorm(x, mean = xo, sd = so)
ya <- dnorm(x, mean = xa, sd = sa)
palette("Tableau 10")
plot(x, ya, type="l", col=3,
xlab="temperature °C", ylab="probability")
lines(x, yb, col=1)
lines(x, yo, col=2)
legend("topright", legend=c("analysis", "background", "observation"),
col=c(3,1,2), lty=1)
次に、最尤法に基づき\(T_1, T_2\)の確率密度分布から最適な推定値を求めてみる。 \(T_1, T_2\)の確率密度分布は正規分布で表すことができる。
\[
\begin{aligned}
p(T_1|T) &= \frac{1}{\sqrt{2\pi}\sigma_1}\exp\left[-\frac{(T_1-T)^2}{2\sigma_1^2}\right] \\
p(T_2|T) &= \frac{1}{\sqrt{2\pi}\sigma_2}\exp\left[-\frac{(T_2-T)^2}{2\sigma_2^2}\right]
\end{aligned}
\tag{1.21}\] 測定値が\(T_1, T_2\)となる確率は、Equation 1.21の二つの積で表すことができる。
\[
L(T|T_1,T_2) = \frac{1}{2\pi\sigma_1\sigma_2}\exp\left[-\frac{(T_1-T)^2}{2\sigma_1^2}-\frac{(T_2-T)^2}{2\sigma_2^2}\right]
\tag{1.22}\]
\(L(\ )\)を尤度函数(likelihood function)という。\(T\)の尤もらしい値は、\(L(T|T_1,T_2)\)が最大になる値である。 指数函数の引数に負号をかけた値
\[
J(T)=\dfrac{1}{2}\left[\frac{(T_1-T)^2}{\sigma_1^2}+\frac{(T_2-T)^2}{\sigma_2^2}\right]
\]
が最小になれば、\(L(T|T_1,T_2)\)の最大値が求まる。 \(J(\ )\)をコスト函数(cost function)と呼ぶ。 このような推定法を最尤法(maximum likelihood method)という。 \(\partial J/\partial T=0\)を計算すると、最尤法により求めた重みは最小二乗法で求めた重みと一致する。 ただし、正規分布に従わない場合はこの限りではない。
さらに、リモートセンシングデータを同化する場合について考える。 気温の代わりに遠隔測定された放射輝度\(y=h(T)\)が得られているとする。 \(h(\ )\)を観測演算子(observation operator)呼ぶ。 観測演算子は、気温から放射輝度のような変数変換だけでなく、空間内挿も含む。
気温の第一推定値は\(T_\mathrm{b}\)、予報誤差は\(\varepsilon_\mathrm{b}\)で表すことにする。 放射輝度の観測値は、\(y_\mathrm{o} = h(T_\mathrm{t}) + \varepsilon_\mathrm{o}\)と表すことができる。 \(\varepsilon_\mathrm{o}\)は観測誤差で、観測誤差と予報誤差は正規分布に従うと仮定する。 イノベーションを誤差で表すと
\[
y_\mathrm{o} - h(T_\mathrm{b})=\varepsilon_\mathrm{o}-H\varepsilon_\mathrm{b}
\] となる。 ここで
\[
H=\frac{\partial h}{\partial T}
\]
である。
最小二乗法で問題を解く。 Equation 1.20 の形式で解析値\(T_\mathrm{a}\)を表すと
\[
T_\mathrm{a} = T_\mathrm{b} + w(y_\mathrm{o}-h(T_\mathrm{b})) = T_\mathrm{b} + w(\varepsilon_\mathrm{o}-H\varepsilon_\mathrm{b})
\tag{1.23}\]
となる。 すなわち、解析誤差は
\[
\varepsilon_\mathrm{a} = \varepsilon_\mathrm{b} + w(\varepsilon_\mathrm{o}-H\varepsilon_\mathrm{b})
\]
解析値の分散は
\[
\sigma_\mathrm{a}^2 = \sigma_\mathrm{b}^2 + w^2(\sigma_\mathrm{o}^2+\sigma_\mathrm{b}^2H^2)-2w\sigma_\mathrm{b}^2H
\tag{1.24}\]
となる。 \(w\)で微分して最適な重みを求めると \[
w=\sigma_\mathrm{b}^2H(\sigma_\mathrm{o}^2+\sigma_\mathrm{b}^2H^2)^{-1}
\tag{1.25}\]
となる。 \(H\)でスケールされた重み
\[
wH=\frac{\sigma_\mathrm{b}^2H^2}{\sigma_\mathrm{o}^2+\sigma_\mathrm{b}^2H^2}=\frac{H^2/\sigma_\mathrm{o}^2}{1/\sigma_\mathrm{b}^2+H^2/\sigma_\mathrm{o}^2}
\]
は0と1の間の値を取る。 観測の分散が大きい(\(\sigma_\mathrm{o}^2 \gg \sigma_\mathrm{b}^2H^2\))とき、解析値は第一推定値にほぼ等しくなる(\(T_\mathrm{a} \approx T_\mathrm{b}\))。 逆に予測の分散が大きい(\(\sigma_\mathrm{b}^2H^2 \gg \sigma_\mathrm{o}^2\))とき、解析値は観測値に近づく(\(T_\mathrm{a} \approx wy_\mathrm{o}\))。
Equation 1.25 を Equation 1.24 に代入すると
\[
\sigma_\mathrm{a}^2 = (1-wH)\sigma_\mathrm{b}^2
\tag{1.26}\]
が得られる。 また、
\[
\dfrac{1}{\sigma_\mathrm{a}^2}=\dfrac{1}{\sigma_\mathrm{b}^2}+\frac{H^2}{\sigma_\mathrm{o}^2}
\tag{1.27}\]
と表すこともできる。 この場合でも、解析精度は第一推定値の精度と観測の精度との和で表される。
最尤法において、観測演算子を含む場合のコスト函数は、
\[
J(T)=\dfrac{1}{2}\left[\frac{(T_\mathrm{b}-T)^2}{\sigma_\mathrm{b}^2}+\frac{(y_\mathrm{o}-h(T))^2}{\sigma_\mathrm{o}^2}\right]
\tag{1.28}\]
で表すことができる。
\(T_\mathrm{b}=2.0^\circ\)C, \(\sigma_\mathrm{b}=2.0^\circ\)C という第一推定値と予報誤差の標準偏差を得たとする。
- \(T_\mathrm{o}=0.0^\circ\)C, \(\sigma_\mathrm{o}=1.0^\circ\)C のとき、\(T_\mathrm{a}\)と\(\sigma_\mathrm{a}\)を求めよ。答: \(T_\mathrm{a}=0.40^\circ\)C, \(\sigma_\mathrm{a}=\sqrt{4/5}\approx 0.89^\circ\)C
- \(T_\mathrm{o}=0.0^\circ\)C, \(\sigma_\mathrm{o}=2.0^\circ\)C のとき、\(T_\mathrm{a}\)と\(\sigma_\mathrm{a}\)を求めよ。答: \(T_\mathrm{a}=1.0^\circ\)C, \(\sigma_\mathrm{a}=\sqrt{2}\approx 1.4^\circ\)C
ベクトル場に対する解析
Section 1.5 では1変数(気温)の1点について考えたが、ここでは多変数からなる複数の点に拡張する。 モデルでは幾何形状に応じて、通常変数を2次元や3次元配列に格納する。 データ同化では、全ての変数の全ての点が表す場を状態ベクトル(1次元)️\(\mathbf{x}\)に格納する。
以下 Lorenc (1986) に基づいて解析方程式を導出する。 Section 1.3 で学んだBayesの定理は
\[
P(A|B) \propto P(B|A)P(A)
\]
と表すことができる。 事象AとBは次のように表すことができる。
- 事象A
-
場が実際に生じた\(\mathbf{x}_\mathrm{t}\)となること、\(\mathbf{x} = \mathbf{x}_\mathrm{t}\)である。 ここで添字の\(\mathrm{t}\)は真値を意味する。
- 事象B
-
観測ベクトル\(\mathbf{y}\)が得られた観測\(\mathbf{y}_\mathrm{o}\)となること、\(\mathbf{y}=\mathbf{y}_\mathrm{o}\)である。
「最良」推定は、
最小分散推定(平均)
\[
\mathbf{x}_\mathrm{a} = \int\mathbf{xP}_\mathrm{a}\mathrm{d}\mathbf{x}
\]
または最大後験推定(モード)、\(\mathbf{P}_\mathrm{a}(\mathbf{x})\)が最大になるような\(\mathbf{x}=\mathbf{x}_\mathrm{a}\)のいずれかである。 ここで\(\mathrm{a}\)は解析を表す。
先験確率とは、観測を行う前の状態\(\mathbf{x}\)についての知識である。 スカラーの場合に誤差は分からないが、分散は既知とする仮定と同様に背景値は真値と同じ確率密度分布を持つと仮定する。 そのような背景値が得られる予報モデルを完全モデル(perfect model)と呼ぶ。
\[
P(\mathbf{x}=\mathbf{x}_\mathrm{t}) = P(\mathbf{x} - \mathbf{x}_\mathrm{b})
\]
観測は偶然誤差が含まれている。 これは、真の観測値\(\mathbf{y}_1 = \mathbf{y}_\mathrm{t}\)が与えられたときの誤差を表す。
\[
P(\mathbf{y} = \mathbf{y}_\mathrm{o}|\mathbf{y}_1 = \mathbf{y}_\mathrm{t}) =
P_\mathrm{o}(\mathbf{y}_1 - \mathbf{y}_\mathrm{o})
\]
Bayes推定に必要な\(P(B|A)\)つまり\(P(\mathbf{y} = \mathbf{y}_\mathrm{o}|\mathbf{x} = \mathbf{x}_\mathrm{t})\)を\(P_{\mathrm{of}}(\mathbf{y}_\mathrm{o} - \mathbf{y}_\mathrm{f})\) で表す。 ここで
\[
\mathbf{y} = H(\mathbf{x}_\mathrm{t})
\]
は観測演算子(観測の順モデル)である。
\(H\)が完全なら\(P_\mathrm{of}(\mathbf{y}_\mathrm{o} - \mathbf{y}_\mathrm{f}) = P_\mathrm{o}(\mathbf{y}_1 - \mathbf{y}_\mathrm{o})\)であり、観測には偶然誤差だけが含まれる。 実際には\(H\)はモデル誤差を含んでいる。 モデル誤差の確率密度を
\[
P(\mathbf{y}_1 = \mathbf{y}_\mathrm{t}|\mathbf{x} = \mathbf{x}_\mathrm{t}) =
P_\mathrm{f}(\mathbf{y}_1 - \mathbf{y}_\mathrm{t})
\]
で表す。
\(B'\)を\(b'\)から\(b' + \mathrm{d}b'\)の間にある確率とすると、\(P(A') = \int P(A'|B')P(B')\mathrm{d}b'\)を用いて \[
P(\mathbf{y} = \mathbf{y}_\mathrm{o}|\mathbf{x} = \mathbf{x}_\mathrm{t}) =
\int P(\mathbf{y} = \mathbf{y}_\mathrm{o}|\mathbf{x} = \mathbf{x}_\mathrm{t}\,\text{and}\,\mathbf{y}_1 = \mathbf{y}_\mathbf{t})P(\mathbf{y}_1 = \mathbf{y}_\mathrm{t}|\mathbf{x} = \mathbf{x}_\mathrm{t})\mathrm{d}\mathbf{y}_1
\]
つまり
\[
P_{\mathrm{of}}(\mathbf{y}_\mathrm{o} - \mathbf{y}_\mathrm{f}) =
\int P_\mathrm{o}(\mathbf{y}_1 - \mathbf{y}_\mathrm{o})P_\mathrm{f}(\mathbf{y}_1 - \mathbf{y}_\mathrm{f})\mathrm{d}\mathbf{y}_1
\tag{1.29}\]
よって解析誤差共分散は
\[
P_\mathrm{a}(\mathbf{x}) =
P(\mathbf{x} = \mathbf{x}_\mathrm{t}|\mathbf{y} = \mathbf{y}_\mathrm{o})
\propto P(\mathbf{y} = \mathbf{y}_\mathrm{o}|\mathbf{x} = \mathbf{x}_\mathrm{t})P(\mathbf{x} = \mathbf{x}_\mathrm{t})
\] \[
\begin{aligned}
P_\mathrm{a}(\mathbf{x}) &= P_{\mathrm{of}}(\mathbf{y}_\mathrm{o} - H(\mathrm{x}))P_\mathrm{b}(\mathbf{x} - \mathbf{x}_\mathrm{b})\\
&= \left\{\int P_\mathrm{o}(\mathbf{y}_1 - \mathbf{y}_\mathrm{o})P_\mathrm{f}(\mathbf{y}_1 - H(\mathbf{x}))\mathrm{d}\mathbf{y}_1\right\}P_\mathrm{b}(\mathbf{x} - \mathbf{x}_\mathrm{b})
\end{aligned}
\] となる。
背景誤差\(P_\mathrm{b}(\mathbf{x} - \mathbf{x}_\mathrm{b})\)と観測誤差\(P_{\mathrm{of}}(\mathbf{y}_\mathrm{o} - H(\mathrm{x}))\)とは無相関で、確率密度分布がガウス型である仮定する。
\[
P_\mathrm{b}(\mathbf{x} - \mathbf{x}_\mathrm{b}) \propto
\exp\left[-\frac{1}{2}(\mathbf{x} - \mathbf{x}_\mathrm{b})^\mathrm{T}\mathbf{B}^{-1}(\mathbf{x} - \mathbf{x}_\mathrm{b})\right]
\] \[
P_\mathrm{o}(\mathbf{y} - \mathbf{y}_\mathrm{o}) \propto
\exp\left[-\frac{1}{2}(\mathbf{y} - \mathbf{y}_\mathrm{o})^\mathrm{T}\mathbf{O}^{-1}(\mathbf{y} - \mathbf{y}_\mathrm{o})\right]
\] \[
P_\mathrm{f}(\mathbf{y} - \mathbf{y}_\mathrm{f}) \propto
\exp\left[-\frac{1}{2}(\mathbf{y} - \mathbf{y}_\mathrm{f})^\mathrm{T}\mathbf{F}^{-1}(\mathbf{y} - \mathbf{y}_\mathrm{f})\right]
\]
ここで
\[
\mathbf{B} = \mathbb{E}[(\mathbf{x}_\mathrm{b} - \mathbf{x}_\mathrm{t})(\mathbf{x}_\mathrm{b} - \mathbf{x}_\mathrm{t})^\mathrm{T}]
\]
\[
\mathbf{O} = \mathbb{E}[(\mathbf{y}_\mathrm{o} - \mathbf{y}_\mathrm{t})(\mathbf{y}_\mathrm{o} - \mathbf{y}_\mathrm{t})^\mathrm{T}]
\]
\[
\mathbf{F} = \mathbb{E}[(\mathbf{y}_\mathrm{t} - H(\mathbf{x}_\mathrm{t}))(\mathbf{y}_\mathrm{t} - H(\mathbf{x}_\mathrm{t}))^\mathrm{T}]
\]
である。 以下\(\mathbf{R} \equiv \mathbf{O} + \mathbf{F}\)と書く。
Equation 1.29 で定義した\(P_{\mathrm{of}}\)は次のように表すことができる。
\[
P_{\mathrm{of}} \propto \exp\left[\frac{1}{2}(\mathbf{y}_\mathrm{o} - \mathbf{y}_\mathrm{t})^\mathrm{T}\mathbf{R}^{-1}(\mathbf{y}_\mathrm{o} - \mathbf{y}_\mathrm{t})\right]
\] 最小分散推定と最大後験推定は一致する。
最大後験推定において、\(P_\mathrm{a}(\mathbf{x})\)の最大化は、コスト函数\(J=-\ln P_\mathrm{a}(\mathbf{x})\)の最小化と等価である。 \[
J = \frac{1}{2}[\mathbf{y}_\mathrm{o} - H(\mathbf{x})]^\mathrm{T}\mathbf{R}^{-1}
[\mathbf{y}_\mathrm{o} - H(\mathbf{x})] + \frac{1}{2}(\mathbf{x} - \mathbf{x}_\mathrm{b})^\mathrm{T}\mathbf{B}^{-1}(\mathbf{x} - \mathbf{x}_\mathrm{b})
\]
観測演算子を線型化する。 \[
H(\mathbf{x} + \mathrm{d}\mathbf{x}) \approx H(\mathbf{x}) + \mathbf{H}\mathrm{d}\mathbf{x}
\] ここで\(\mathbf{H} = \partial H/\partial\mathbf{x}\)は観測演算子のヤコビアンである。
\(J\)を最小にする解析値\(\mathbf{x} = \mathbf{x}_\mathrm{a}\)は
\[
0 = \mathbf{H}^\mathrm{T}\mathbf{R}^{-1}[\mathbf{y}_\mathrm{o} - H(\mathbf{x}_\mathrm{a})] + \mathbf{B}^{-1}(\mathbf{x}_\mathrm{b} - \mathbf{x}_\mathrm{a})
\]
より
\[
\begin{aligned}
\mathbf{x}_\mathrm{a} &= \mathbf{x}_\mathrm{b} + (\mathbf{H}^\mathrm{T}\mathbf{R}^{-1}\mathbf{H} + \mathbf{B}^{-1})^{-1}\mathbf{H}^\mathrm{T}\mathbf{R}^{-1}[\mathbf{y}_\mathrm{o} - H(\mathbf{x}_\mathrm{b})] \\
&= \mathbf{x}_\mathrm{b} + \mathbf{B}\mathbf{H}^\mathrm{T}(\mathbf{H}\mathbf{B}\mathbf{H}^\mathrm{T} + \mathbf{R})^{-1}[\mathbf{y}_\mathrm{o} - H(\mathbf{x}_\mathrm{b})]
\end{aligned}
\]
が得られる。 状態ベクトル\(\mathbf{x}\)の大きさを\(n\)、観測ベクトルの大きさを\(m\)とすると、最初の式では\(n\times n\)、二つ目の式では\(m\times m\)の行列の逆を計算する必要がある。
この二つはWoodsburyの式(Golub and Van Loan 2013)を用いて示すこともできるが、以下のようにすると確認できる(Rodgers 2000)。
\[
\mathbf{H}^\mathrm{T}\mathbf{R}^{-1}(\mathbf{HBH}^\mathrm{T} +\mathbf{R}) = (\mathbf{H}^\mathrm{T}\mathbf{R}^{-1}\mathbf{H} + \mathbf{B}^\mathrm{-1})\mathbf{BH}^\mathrm{T}
\]
の両辺に左から\((\mathbf{H}^\mathrm{T}\mathbf{R}^{-1}\mathbf{H} + \mathbf{B}^\mathrm{-1})^{-1}\)、右から\((\mathbf{HBH}^\mathrm{T} +\mathbf{R})^{-1}\)を掛けると \[
(\mathbf{H}^\mathrm{T}\mathbf{R}^{-1}\mathbf{H} + \mathbf{B}^\mathrm{-1})^{-1}\mathbf{H}^\mathrm{T}\mathbf{R}^{-1} = \mathbf{BH}^\mathrm{T}(\mathbf{HBH}^\mathrm{T} +\mathbf{R})^{-1}
\]
が得られる。
線型ガウス型の場合の解析誤差共分散の期待値は
\[
\mathbb{E}[(\mathbf{x}_\mathrm{a} - \mathbf{x}_\mathrm{t})(\mathbf{x}_\mathrm{a} - \mathbf{x}_\mathrm{t})^\mathrm{T}] = \mathbf{B} - \mathbf{BH}^\mathrm{T}(\mathbf{HBH}^\mathrm{T} +\mathbf{R})^{-1}\mathbf{HB}
\tag{1.30}\]
となる。
Golub, G. H., and C. F. Van Loan, 2013:
Matrix computations - 4th edition. fourth. Johns Hopkins University Press,.
Kalnay, E., 2003: Atmospheric modeling, data assimilation and predictability. Cambridge University Press,.
Lorenc, A. C., 1986: Analysis methods for numerical weather prediction. Quart. J. Roy. Meteor. Soc., 112, 1177–1194.
Rodgers, C. D., 2000: Inverse methods for atmospheric sounding: Theory and practice. World Scientific,.