機械学習は、データを学習して推定を改善する手法である。
まず、Chase et al. (2022 ) に基づいて、統計的学習と呼ばれる古典的な手法について述べる。
機械学習は、物理法則に依らずデータに基づく経験的な手法で、訓練データセットに対してパラメタを適合(学習)し、あらかじめ定めた損失(コスト)を最適化する。
機械学習は、教師あり (supervised)と教師なし (unsupervised)に大別される。 教師あり学習には入力の特徴量 (feature)に対する出力のラベル (label)を用いるが、教師なし学習にはラベルを用いない。
特徴量は説明変数、予測因子、予測変数(predictor)とも呼ばれ、ベクトルまたは行列\(\mathbf{X}\) で表される。 ラベルは目的変数(target)や予測対象、被予測変数(predictand)とも呼ばれ、スカラーまたはベクトル\(y\) で表される。
教師あり学習は、回帰(regression)と分類(classification)があり、回帰では連続した出力、分類では離散的な出力を得る。 どちらも訓練データを用いて、予測するために最適な重み(閾値)を求める。 重みは、誤差(error)を最小に、ラベルの確率を最大にするように決める。
線型回帰
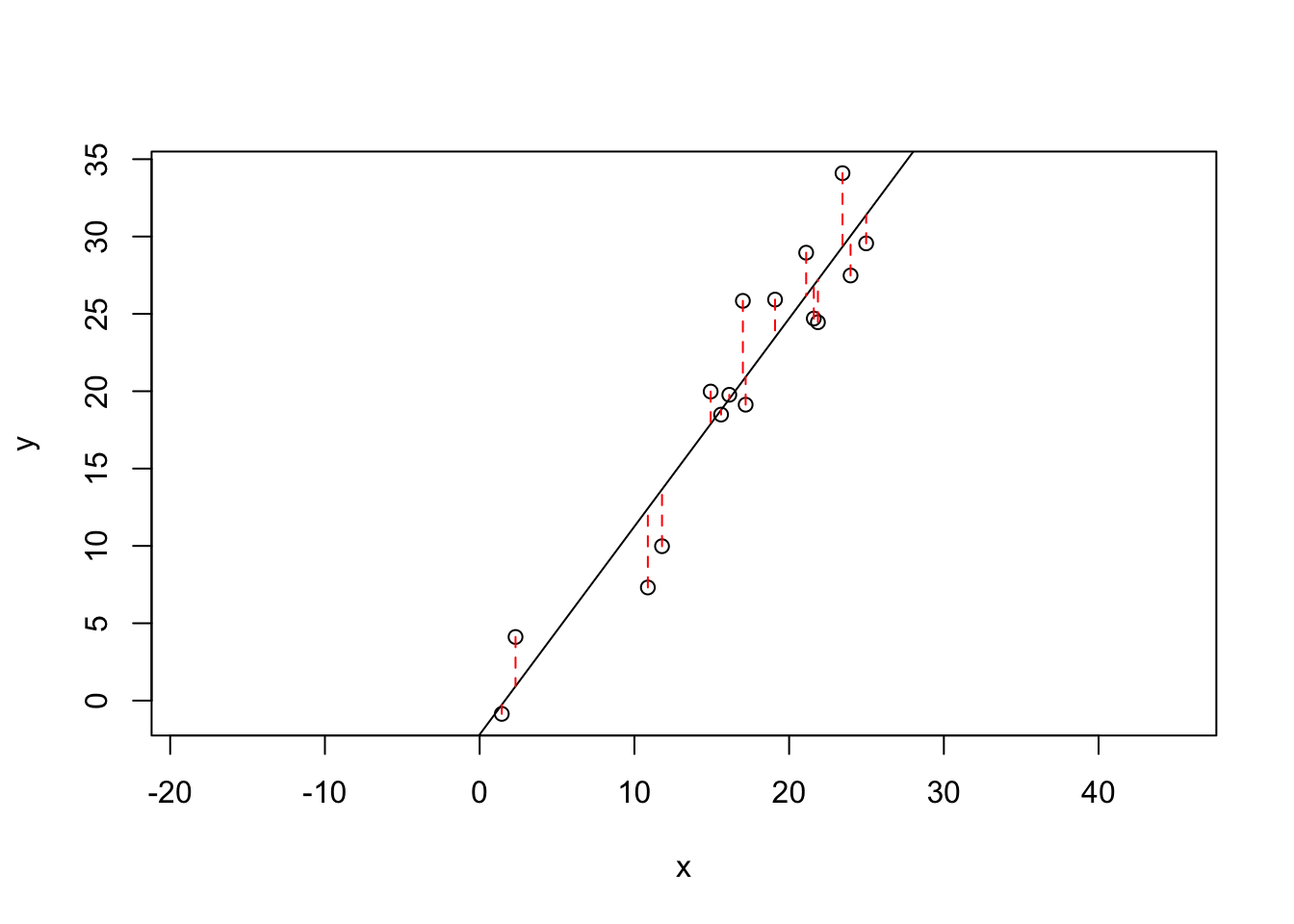
最も簡単な回帰は線型回帰 Section 1.1 \(\hat{y}\) を重付き平均で求める。
\[
\hat{y} = \sum_{i=1}^{i=D}w_ix_i + b
\tag{6.1}\]
\(D\) は特徴量の数で\(b\) はバイアス項である。
重み\(w_i\) を求めるため、損失函数(loss function)を最小化する。
残差和二乗(RSS: residual summed squared)損失は で定義される。 \(y_i\) はデータ点、\(\hat{y}_j\) は予報されたデータ点、\(N\) は訓練データセットにあるデータ点の数である。
Code
set.seed (514 )<- 1.2 <- 1 <- runif (16 , 0 , 25 )<- w * x + rnorm (length (x), 0 , 3 )<- lm (y ~ x)plot (x, y, asp= 1 )abline (fit)<- fit$ coefficients[1 ] + fit$ coefficients[2 ] * xfor (i in 1 : length (x)) {lines (c (x[i], x[i]), c (y[i], yhat[i]), col= "red" , lty= 2 )
データにノイズが含まれている場合、学習が不安定になる。 これを回避する方法が、正則化(regularization)である。
リッジ(ridge)回帰では、L2損失
\[
\text{RSS}_{\mathrm{L2}} = \sum_{j=1}^{N}(y_j-\hat{y}_j)^2 + \lambda\sum_{i=0}^{D}w_i^2
\tag{6.3}\]
ラッソ(Lasso)回帰では(L1)損失
\[
\text{RSS}_{\mathrm{L2}} = \sum_{j=1}^{N}(y_j-\hat{y}_j)^2 + \lambda\sum_{i=0}^{D}|w_i|
\tag{6.4}\]
を用いる。 二つを組み合わせたものがエラスティクネット(elastic net)である。
\[
\mathrm{RSS}_{\mathrm{L2}} = \sum_{j=1}^{N}(y_j-\hat{y}_j)^2 + \sum_{i=0}^{D}[\alpha w_i^2 + (1-\alpha)|w_i|]
\tag{6.5}\]
ロジスティック回帰
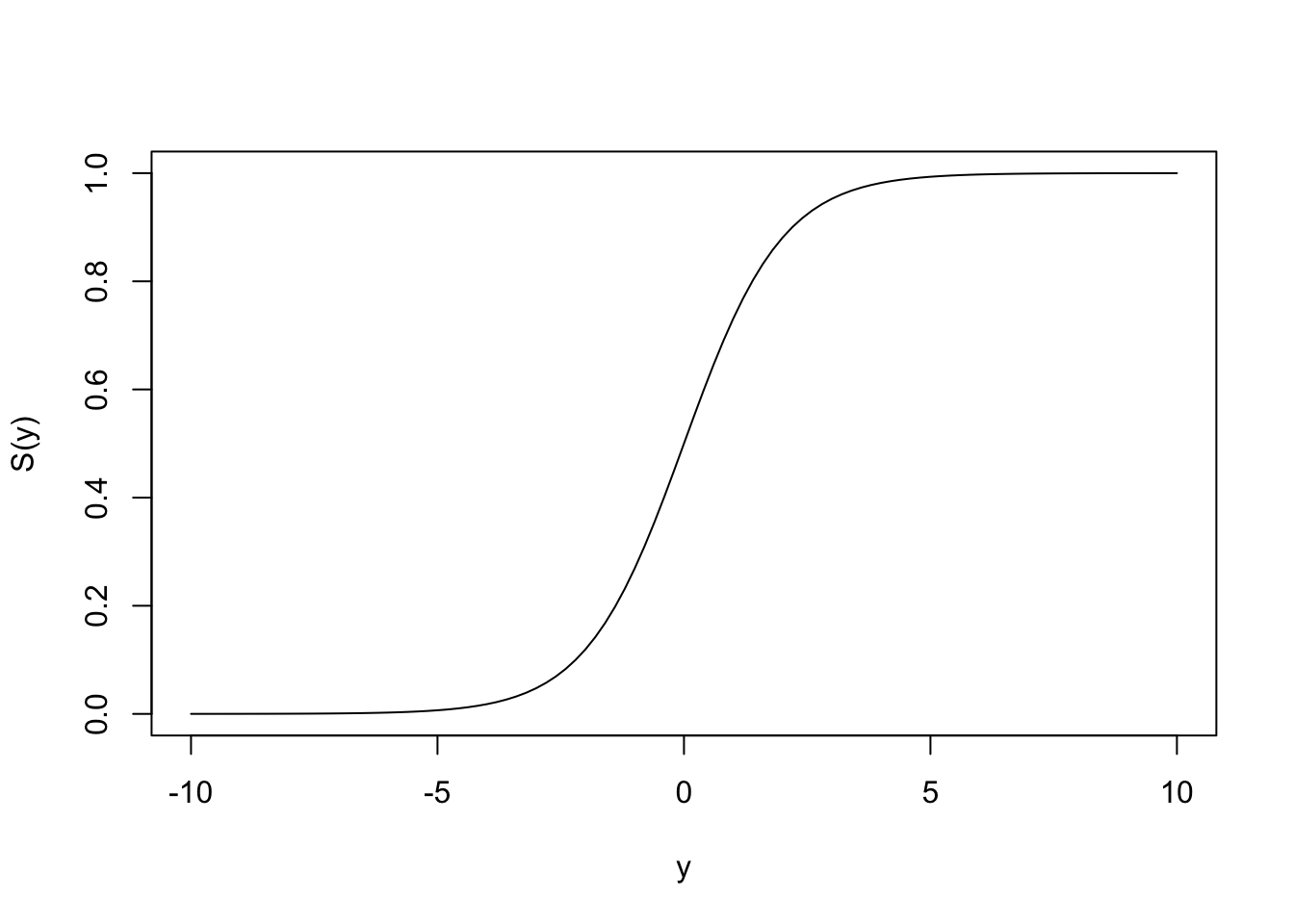
ロジスティク回帰は分類に用いられ、出力にシグモイド(sigmoid)函数を適用する。
\[
S(y) = \frac{1}{1 + e^{-y}}
\tag{6.6}\]
Code
curve (1 / (1 + exp (- x)), - 10 , 10 , xlab= "y" , ylab= "S(y)" )
ロジスティク回帰を用いた分類の損失函数は次のようになる。
\[
\mathrm{loss} = \sum_{i=0}^{i=D}-y_i\log[S(\hat{y})] + (1 + y_i)\log[1 - S(\hat{y})]
\tag{6.7}\]
ナイーブベイズ
ナイーブベイズは、ベイズの定理 Section 1.3 \(x\) が与えられたとき、ラベル\(y\) の確率密度 \(P(y|x)\) を求める。(Section 1.3 \(y\) と\(x\) が入れ替わっていることに注意。)
\[
P(y|x) = \frac{P(y)P(x|y)}{P(x)}
\tag{6.8}\]
ナイーブと呼ばれるのは、現実には必ずしも当てはまらない、全ての入力特徴量\(x\) が独立で、\(P(x|y)\) が正規分布のようなモデル化されたもので表されるという仮定を用いているためである。
予測は次の式で与えられる。
\[
\hat{y} = \mathrm{argmax}\left\{\log[P(y)] + \sum_{i=0}^N\log[P(x_i|y)]\right\}
\tag{6.9}\]
決定木
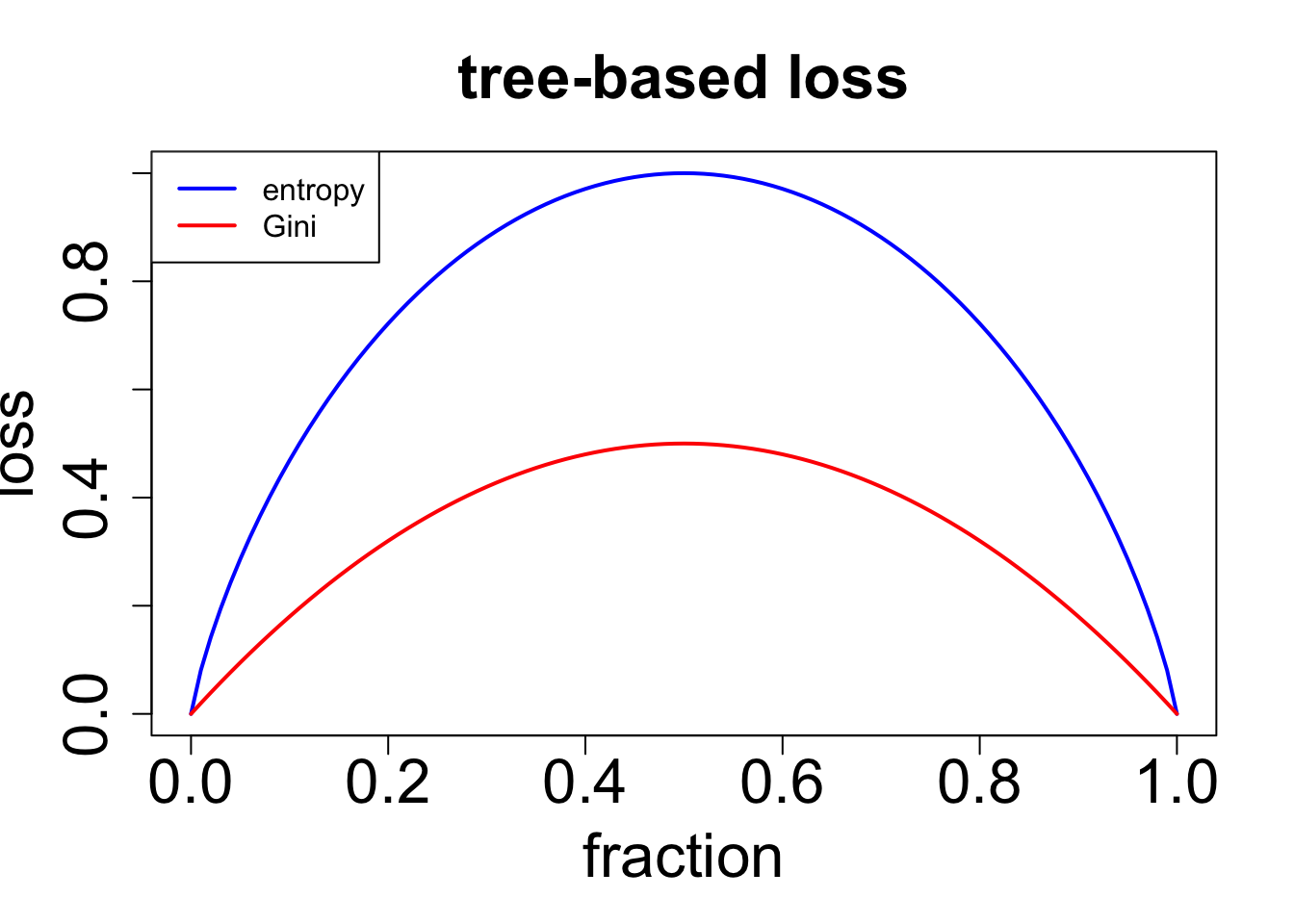
決定木(けっていぎ)を用いた分類では、ジニ不純度やエントロピーを最小化するようにデータを分ける。
\[
\mathrm{Gini} = \sum_{i=0}^{i=k}p_i(1 - p_i)
\tag{6.10}\] \[
\mathrm{entropy} = \sum_{i=0}^{i=k}p_i\log_2(p_i)
\tag{6.11}\]
Code
<- function (p) {2 * p * (1 - p)<- function (p){ifelse (p == 0 | p == 1 ,0 ,- p * log2 (p) - (1 - p) * log2 (1 - p))curve (calc.entropy, 0 , 1 , col= "blue" , lwd= 2 ,xlab= "fraction" , ylab= "loss" , main= "tree-based loss" ,cex.main= 2 , cex.axis= 2 , cex.lab= 2 )curve (calc.gini, 0 , 1 , col= "red" , lwd= 2 , add= TRUE )legend ("topleft" , c ("entropy" , "Gini" ), lwd= 2 , col= c ("blue" , "red" ))
サポートベクトルマシン
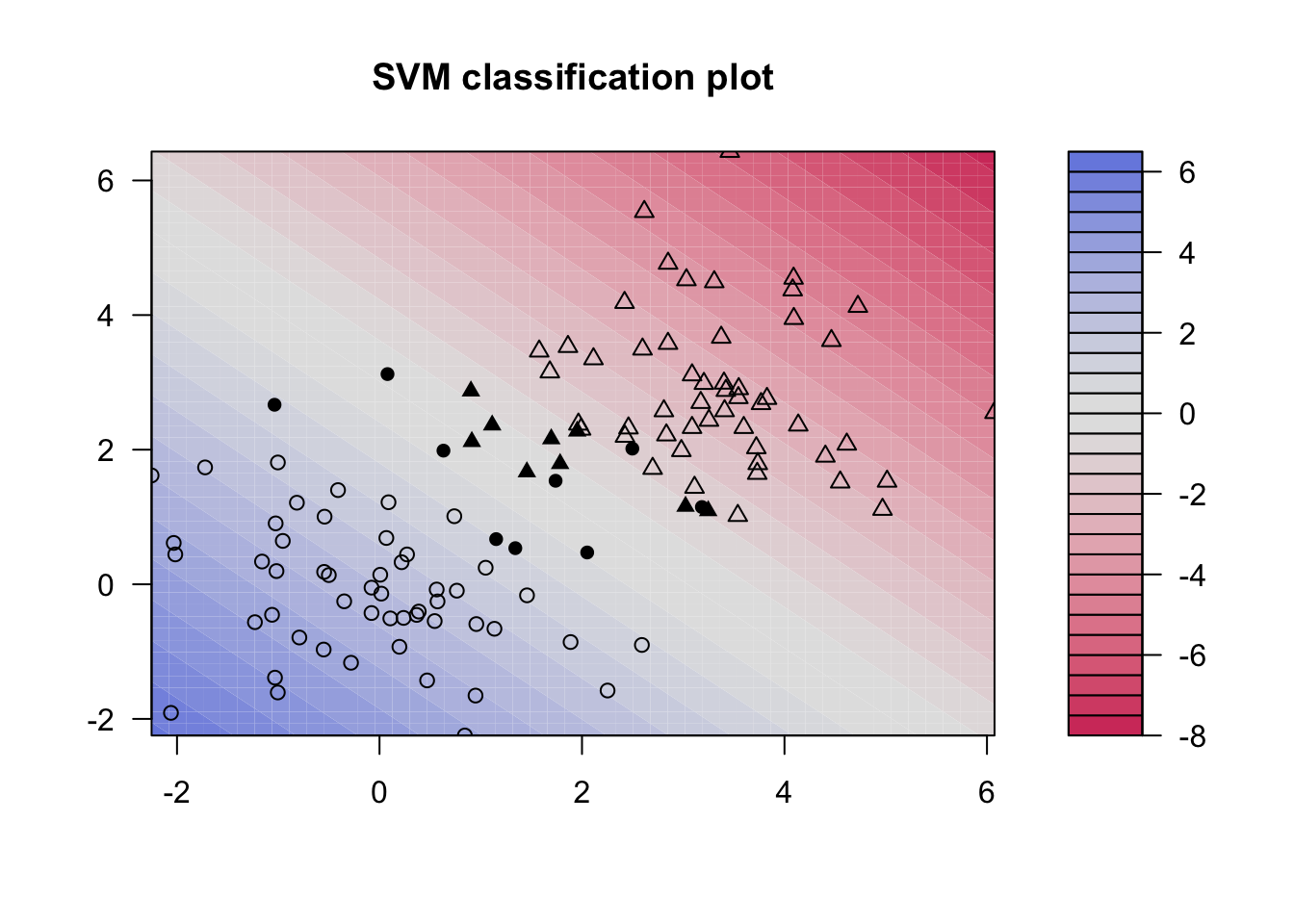
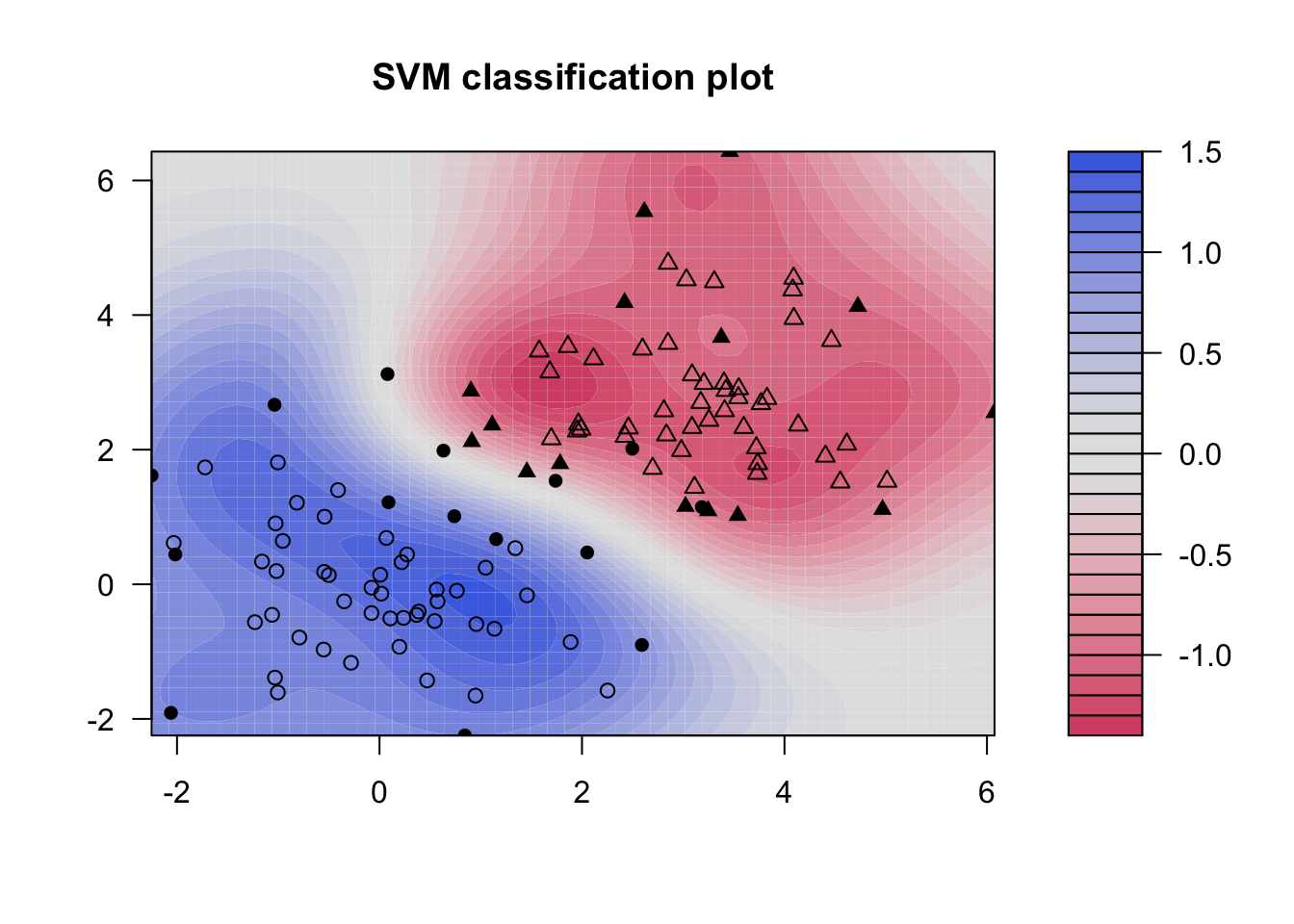
サポートベクトルマシン(SVM: Support Vector Machine)は類似したデータの集まり(クラス)を分けるマージン(margin)を最大化する手法である。
\[
\hat{y} = \mathbf{w}^\mathrm{T}\mathbf{x} + b
\tag{6.12}\]
ここで\(\mathbf{w}\) は重みベクトル、\(\mathbf{x}\) は特徴量、\(b\) はバイアス。 分類では、右辺の符号のみを用いる。 線型手法とは異なり、線型境界にマージンが最大になるように\(\mathbf{w}^\mathrm{T}\) を決める。
\[
\text{margin} = \frac{1}{\mathbf{w}^\mathrm{T}\mathbf{w}}
\]
Code
library (kernlab)set.seed (514 )<- rbind (matrix (rnorm (120 ), ncol= 2 ), matrix (rnorm (120 , 3 ), ncol= 2 ))<- matrix (c (rep (1 , 60 ), rep (- 1 , 60 )))
Code
<- ksvm (x, y, type= "C-svc" , kernel= "vanilladot" , kpar= list ())plot (svp.vd, data= x)
Code
<- ksvm (x, y, type= "C-svc" , kpar= list ())plot (svp.rbf, data= x)
カーネル法
カーネル法は、函数近似や内挿のような数値解析や、偏微分方程式のメッシュレス解法、ニューラルネットワーク及び機械学習に用いられている (Schaback and Wendland 2006 ) 。
カーネルは、の特徴マップにより学習入力の空間\(\Omega\) を解析が容易な高次元(無限次元)の空間(再生核ヒルベルト空間)\(\mathcal{F}\) に写像する。 \(\mathcal{F}\) では線型手法を用いる。
カーネルは一般的に
\[
K: \Omega\times\Omega\rightarrow\mathbb{R}
\tag{6.13}\]
と定義される。
特徴マップ\(\Phi: \Omega\rightarrow \mathcal{F}\) について、カーネルは 全ての\(x,y\in \Omega\) に対し、内積を用いて
\[
K(x,y):=(\Phi(x),\Phi(y))_{\mathcal{F}}
\tag{6.14}\]
と定義される。
正定値対称カーネルのみを扱う。 対称性は次を満たすことをいう。
\[
K(x,y) = K(y, x)
\tag{6.15}\]
任意の\(n\) に対して要素が \(K(x_i, x_j)\) であるグラム行列 \(\mathbf{K}\) が正定値 Section A.3
例えば、ランダム変数の共分散は標準的なカーネルである。 \(\Omega\) からの標本\(x\) と\(y\) とが類似していれば、相関が高く、カーネルの値は大きな正の値を取る。
よく用いられる、ガウス型カーネルは
\[
K(x,\,y) := \exp(-\|x-y\|^2_2)
\tag{6.16}\]
と表される。
カーネル法は、回帰、サポートベクトルマシン、主成分分析、正準相関解析等に適用されている。
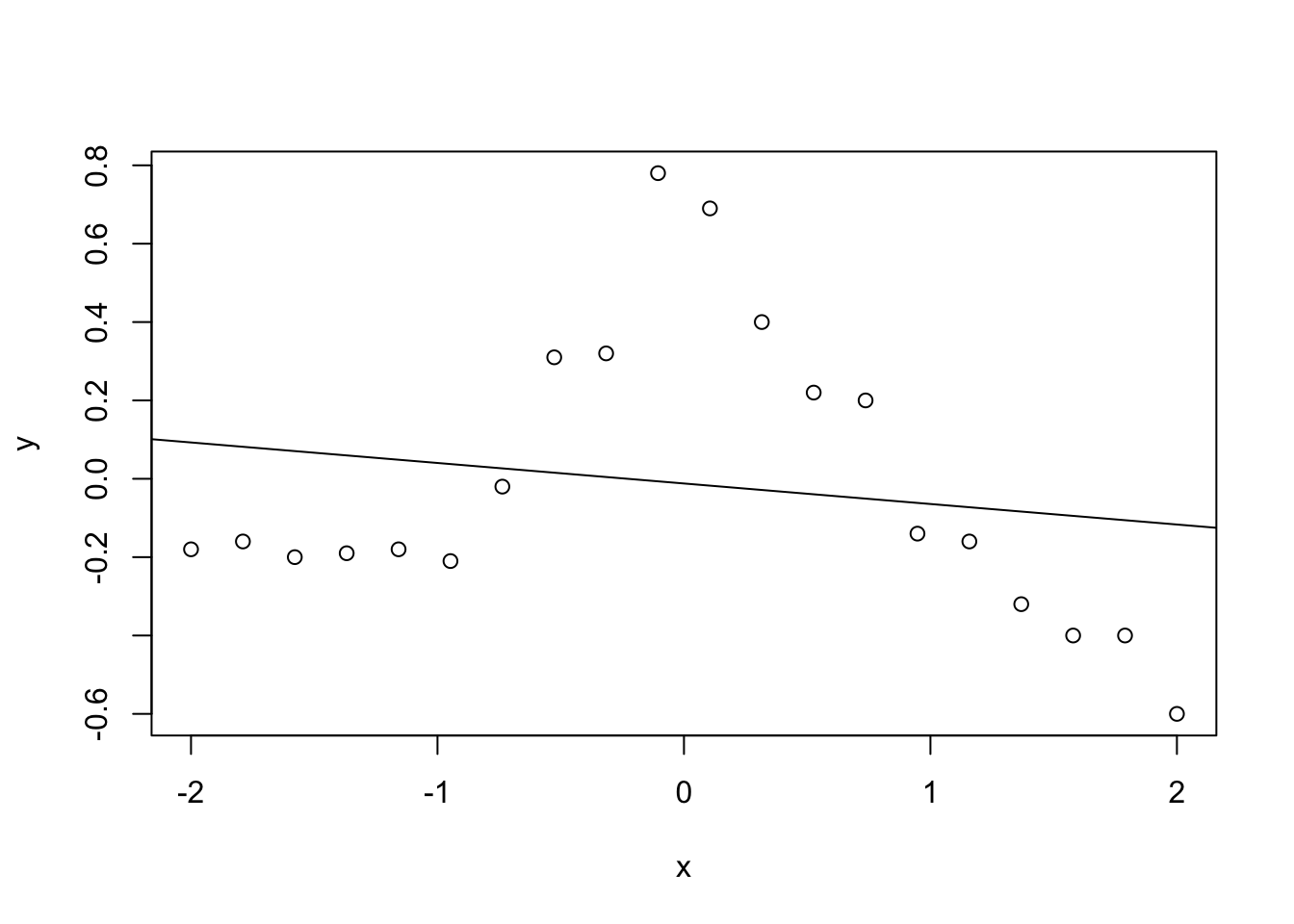
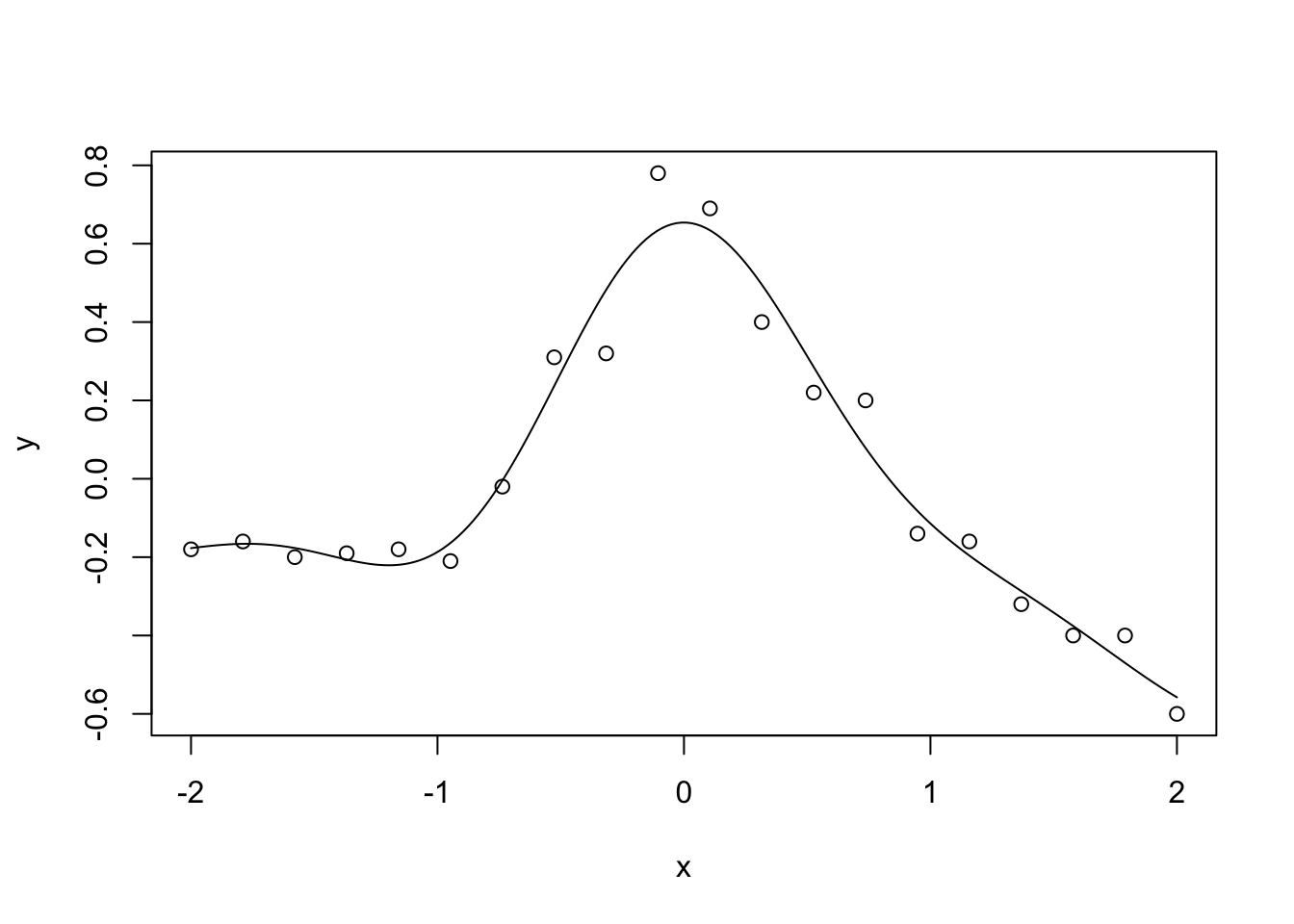
まず、線型回帰とカーネル回帰を比較する (赤穂昭太郎 2008 ) 。
Code
<- 20 <- seq (- 2 , 2 , length.out= n)<- c (- 0.18 , - 0.16 , - 0.2 , - 0.19 , - 0.18 , - 0.21 , - 0.02 , 0.31 , 0.32 , 0.78 , 0.69 , 0.4 , 0.22 , 0.2 , - 0.14 , - 0.16 , - 0.32 , - 0.4 , - 0.4 , - 0.6 )plot (x,y)abline (lm (y ~ x))
Code
<- 0.01 <- function (x, y, beta= 1.0 ) {exp (- beta * (x - y)^ 2 ).10 <- seq (- 2 , 2 , length.out= n* 10 )<- outer (x, x, calc.ga)<- solve ((kmat + lambda * diag (n)), y).10 <- outer (x.10 , x, calc.ga) %*% alphaplot (x, y)lines (x.10 , y.10 )
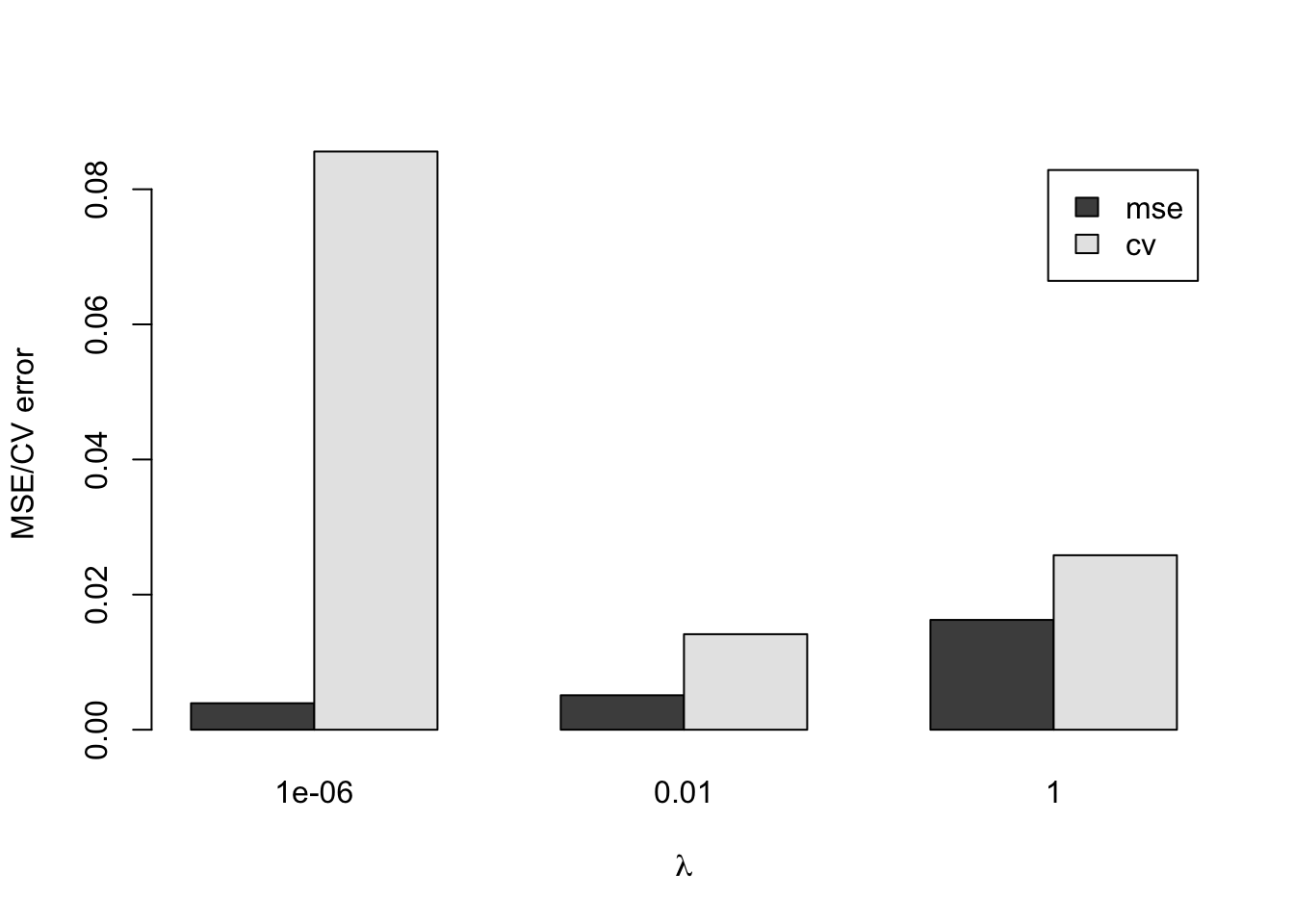
交差検証
Code
<- function (y, yf) {mean ((y - yf)^ 2 )<- function (y, yf, hii){mean (((y - yf) / (1 - hii))^ 2 )= c (1.0e-6 , 0.01 , 1.0 )= rep (0 , length (lambda))= rep (0 , length (lambda))<- 1 for (l in lambda) {<- solve ((kmat + l * diag (n)), kmat)<- diag (hmat)<- solve ((kmat + l * diag (n)), y)<- outer (x, x, calc.ga) %*% alpha<- calc.mse (y, yf)<- calc.cv (y, yf, hii)<- i + 1 <- rbind (mse, cv)rownames (error) <- c ("mse" , "cv" )colnames (error) <- lambdabarplot (error, beside= TRUE , legend= TRUE ,xlab= expression (lambda), ylab= "MSE/CV error" )
カーネル密度推定は確率密度分布を推定する手法である。
独立同分布(i.i.d.: independent and identically distributed)の標本から確率密度分布を推定する。
\[
\hat{f}_h(x) = \frac{1}{n}\sum_{i=1}^n K_h(x - x_i)
= \frac{1}{nh}\sum_{i=1}^n K\left(\frac{x - x_i}{h}\right)
\tag{6.17}\]
ここで、\(K\) : 非負のカーネル、\(K_h(x) = K(x/h)/h\) : スケールされたカーネル、\(h\) : バンド幅
ガウシアンカーネルを用いると次のように書ける。
\[
\hat{f}_h(x) = \frac{1}{n}\frac{1}{h\sigma\sqrt{2\pi}}\sum_{i=1}^n
\exp\left[\frac{-(x - x_i)^2}{2(h\sigma)^2}\right]
\tag{6.18}\]
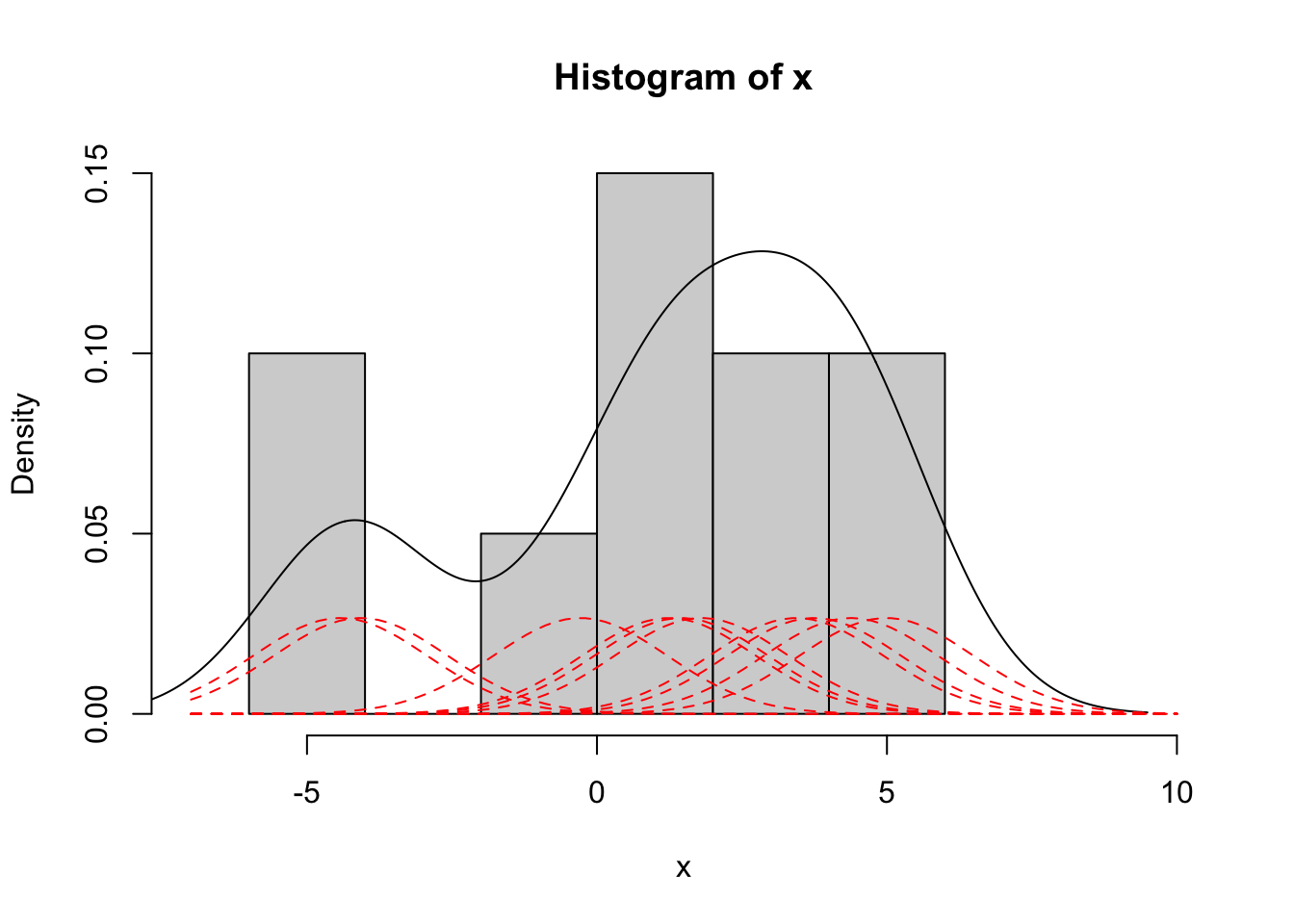
ヒストグラムと比較する。
Code
set.seed (514 )<- 10 * (runif (10 ) - 0.5 )<- sd (x)hist (x, freq = FALSE , xlim = c (- 7 , 10 ))= 1.5 <- 101 <- seq (- 7 , 10 , length.out = n)lines (density (x, bw = sh), xlim = c (- 7 , 10 ), ylim = c (0 , 0.15 ))for (x1 in x) {lines (xaxis, dnorm (xaxis, mean = x1, sd = sh) / length (x), type = "l" ,lty = 2 , col = "red" )
ニューラルネットワーク
Chase et al. (2023 ) に基づいて、ニューラルネットワークについて述べる。
ニューロンは脳の基礎単位で、電気で信号を伝達する機能を持つ。
単純パーセプトロンはニューロンをモデル化したものである。 最も簡単なパーセプトロンは、入力と出力の2層からなり、二つの出力(0と1)から一つを選択して出力する。
\(n\) 個の入力に対し、\(m\) 個の出力をするパーセプトロンは次の式で表すことができる。
\[
y_j = \sum_{i=1}^n w_{ij}x_i + b_i,\;j = 1, \dots, m
\]
ここで、\(x_i\) は入力、\(y_j\) は出力、\(w_{ij}\) は重み、\(b_i\) はバイアス、\(\sigma()\) は活性化函数である。
ベクトルや行列形式では
\[
\mathbf{y} = \mathbf{Wx} + \mathbf{b}
\]
と表すことができる。
データから重み\(\mathbf{W}\) を決めることにより、単純パーセプトロンは線型分離可能な問題を解くことができるが、非線型で分離不可能な問題は解けない。
単純パーセプトロンの出力に活性化函数\(\sigma()\) を作用させ、中間層(隠れ層)を増やして多層化すると、より複雑な問題を解くことができる。 これを多層パーセプトロンまたは人工ニューラルネットワーク(ANN: artificial neural network)という。
\[
\mathbf{x}_k = \sigma_{k-1}(\mathbf{W}_{k-1}\mathbf{x}_{k-1} + \mathbf{b}_{k-1}) \\
\tag{6.19}\]
ANNの重みは、確率降下学習法(Amari 1967 ; 甘利 1968 ) と誤差逆伝播法(Rumelhart et al. 1986 ) によって求めることができる。 その際、自然勾配を用いることにより速く収束させることができる(Amari 1998 ; 甘利 2001 ) 。
活性化函数がシグモイド函数であれば、各層はロジスティック回帰Section 6.2
自己組織化マップ
自己組織化マップ (SOM: self-organizing map, Kohonen 1982 ) は、教師なし学習のクラスタリングに用いられる手法で、類似したデータを同一のカテゴリにする。 SOMは隠れ層を持たず、出力は2次元に配置された節であり、類似した節が隣接する。 そのため、パターンの遷移が解釈しやすい。
Eckert et al. (1996 ) は、アンサンブル予報にSOMを用いた。 榎本 (2021 ) は日本域に適用してEOFとの比較を行った。
畳み込みニューラルネットワーク
畳み込みニューラルネットワーク(CNN: convolutional neural network)は、画像処理に用いられる畳み込み(フィルタ)を用いて特徴を自動的に抽出する (Fukushima 1980 ) 。 畳み込み層とともに用いられるのが、プーリング(pooling)層である。 プーリング層は低解像度化など次元削減を行い、特徴の抽出を助ける。
2019年10月9日0000UTCにおける台風第19号のひまわり赤外画像に以下の処理を施した。
標準偏差30のガウシアンフィルタでぼかす。
次の式で画像\(I\) のヘシアン\(H\) の行列式の上位95%の座標を抽出。
境界上の座標を除外。
座標の中心を赤い丸で表示。
\[
\det(H) = I_{xx} I_{yy} - I_{xy}^2
\]
Code
library (imager)<- load.image ("figures/hagibis.png" )<- isoblur (img, 30 )<- with (imhessian (img.denoised), 0.1 ^ 2 * (xx* yy - xy^ 2 ))<- threshold (Hdet, "95%" ) |> label ()<- as.data.frame (lab) |> subset (value > 0 & x > 1 & x < width (lab) & y > 1 & y < height (lab))<- aggregate (cbind (x, y) ~ value, data = df, FUN = mean)plot (img, axes = FALSE )with (centers, points (x, y, col= "red" ))
U-netは画像から画像を出力するCNNである。 逆畳み込み(deconvolution)層と逆プーリング(unpooling)層により、次元を復元した出力を得る。 畳み込みやプーリングをエンコーディング、逆畳み込みや逆プーリングをデコーディングといい、全体の流れがU字となることから、名付けられている。 U-netには、スペクトル変換や多重格子法と類似点がある。
トランスフォーマ
カーネル回帰から画像認識、大規模言語モデルへの発展をレビューしたMilanfarのツイート や Kassinos and Alexiadis (2024 ) を参考に大規模言語モデル(LLM: large language model)に用いられるトランスフォーマ(transformer)について述べる。
トランスフォーマはアテンション機構 (Vaswani et al. 2023 ) が重要な役割を果たしている。 アテンション機構は、カーネルをデータで推定する。
トランスフォーマは言語に特化した機械学習手法と思われがちだが、処理されているのはベクトルであり、トランスフォーマで微分方程式を解くこともできる (Kassinos and Alexiadis 2024 ) 。
アテンション機構は、フーリエ変換などの畳み込みと似ており、 単語の頻度を振動数に変換するようなものである。 LLMは学習を元に、入力に対してもっともらしい出力を生成する。
アテンション機構に絞ってみていこう。 \(N\) 個のデータ列のうち\(i\) 番目の入力を \(\mathbf{x}_i\in\mathbb{R}^d\) とする。 3つの重み行列\(\mathbf{W}_K,\,\mathbf{W}_Q,\,\mathbf{W}_v\in\mathbb{R}^{d'\times d}\) により線型変換を行う。重みは学習して決める。
キー: \(\mathbf{K}_i = \mathbf{W}_K\mathbf{x}_i\)
クエリ: \(\mathbf{Q}_i = \mathbf{W}_Q\mathbf{x}_i\)
バリュー: \(\mathbf{V}_i = \mathbf{W}_V\mathbf{x}_i\)
アテンションスコアとは、入力ベクトル列の中の各対\((\mathbf{x}_i,\,\mathbf{x}_j)\) に対するスコアである。
\[
s_{ij} = \frac{\mathbf{Q}_i^\mathrm{T}\mathbf{K}_j}{\sqrt{d'}}
\tag{6.20}\]
これを要素とする行列がスコア行列 \(\mathbf{s}_{ij} \in \mathbb{R}^{N\times N}\) である。
ソフトマックス函数は、入力\(\mathbf{z}=(z_1,\dots,z_K)\in\mathbb{R}^K\) を出力\(\sigma: \mathbb{R}^K\rightarrow(0, 1)^K\) に射影する函数である。 シグモイド函数(\(K=2\) )Equation 6.6 を一般化したもので、統計力学ではボルツマン(ギブス)分布である。
\[
\sigma(\mathbf{z})_i = \frac{\exp(z_{i})}{\sum_j^K\exp(z_{j})}
\]
ボルツマン分布をおさらいする。 理想気体は、粒子(分子)間の相互作用が無視できるほど小さい気体である。 \(k\) 番目の量子状態にある気体の粒子数(占拠数)\(\bar{n}_k\ll 1\) とする。
\[
\bar{n}_k = a\exp\left(-\frac{\varepsilon_k}{T}\right)
\tag{6.21}\]
\(a\) は規格化の条件\(\sum_k\bar{n}_k = N\) によって決まる定数。 Equation 6.21 で与えられる分布がボルツマン分布である。
スコア行列の各行にソフトマックス函数を適用し、アテンション重みを得る。
\[
\mathbf{S}_{ij} = \frac{\exp(s_{ij})}{\sum_k^N\exp(s_{ik})}
\tag{6.22}\]
各ベクトルに対するアテンション重みの和は、ソフトマックスにより1になるので、確率は比較可能となる。
各入力ベクトル\(\mathbf{x}_i\) に対して、アテンション重み\(\mathbf{S}_{ij}\) を用いて、バリューベクトル\(\mathbf{V}_j\) の加重合計として、出力ベクトル\(\mathbf{A}_i\) を計算する。
\[
\mathbf{A}_i = \sum_{j=0}^{N-1}\mathbf{S}_{ij}\mathbf{V}_j
\tag{6.23}\]
自己アテンション機構の最終出力は、長さ\(d'\) のベクトル\(\mathbf{A}_i\) が\(N\) 個連なる列である。各出力ベクトルは対応するアテンションスコアに重みづけされ、入力列全体の影響を受ける。
一見アテンションは恣意的に見えるが、数学や物理学の類似した概念と関連づけることができる。 Equation 6.23 は、離散積分変換と同形であり、カーネル\(\mathbf{S}_{ij}\) により\(\mathbf{V}_j\) を\(\mathbf{A}_i\) に変化する。 Equation 6.23 はフーリエ級数と類似しているが、データから学習したカーネル を用いることが異なる。
離散フーリエ変換では、カーネル\(\exp(-i2\pi kn/N)\) 時系列\(x_n\) は振動数列\(X_k\) に変換される。 \[
X_k = \sum_{n=0}^{N-1} x_n\exp\left(\frac{-i2\pi kn}{N}\right)
\tag{6.24}\]
アテンションスコア Equation 6.20 \(s_{ij}\) は、\(\sqrt{d'}\) でスケールされた\(\mathbf{Q}_i\) と\(\mathbf{K}_j\) の共分散の要素である。 \(\mathbf{Q}_i\) と\(\mathbf{K}_j\) は共に\(\mathbf{x}_i\) の線型変換なので、カーネル \(\mathbf{S}_{ij}\) Equation 6.22 は自己共分散行列の情報を与える。 カーネルが入力\(\mathbf{x}_i\) の自己相関行列である積分変換は、主成分分析と関連するKarhunen-Loève変換である。 カーネルが固定されているフーリエ変換とは異なり、Karhunen-Loève変換はトランスフォーマ同様にデータに依存する。
Amari, S., 1967: A theory of adaptive pattern classifiers.
IEEE Transactions on Electronic Computers ,
EC-16 , 299–307,
https://doi.org/10.1109/PGEC.1967.264666 .
Amari, S., 1998: Natural gradient works efficiently in learning.
Neural Comput. ,
10 , 251–276,
https://doi.org/10.1162/089976698300017746 .
Chase, R. J., D. R. Harrison, A. Burke, G. M. Lackmann, and A. McGovern, 2022: A machine learning tutorial for operational meteorology.
Part I : Traditional machine learning.
Wea. Forecast. ,
37 , 1509–1529,
https://doi.org/10.1175/WAF-D-22-0070.1 .
——, ——, G. M. Lackmann, and A. McGovern, 2023: A machine learning tutorial for operational meteorology.
Part II : Neural networks and deep learning.
Wea. Forecast. ,
38 , 1271–1293,
https://doi.org/10.1175/WAF-D-22-0187.1 .
Eckert, P., D. Cattani, and J. Ambühl, 1996: Classification of ensemble forecasts by means of an artificial neural network.
Meteor. Appl. ,
3 , 169–178, https://doi.org/
https://doi.org/10.1002/met.5060030207 .
Fukushima, K., 1980: Neocognitron:
A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position.
Biological Cybernetics ,
36 , 193–202,
https://doi.org/10.1007/BF00344251 .
Kassinos, S., and A. Alexiadis, 2024: Beyond language:
Applying MLX transformers to engineering physics.
https://doi.org/10.48550/arXiv.2410.04167 .
Kohonen, T., 1982: Self-organized formation of topologically correct feature maps.
Biol. Cybern. ,
43 , 59–69,
https://doi.org/10.1007/BF00337288 .
Rumelhart, D. E., G. E. Hinton, and R. J. Williams, 1986: Learning representations by back-propagating errors.
Nature ,
323 , 533–536,
https://doi.org/10.1038/323533a0 .
Schaback, R., and H. Wendland, 2006: Kernel techniques:
From machine learning to meshless methods.
Acta Numerica ,
15 , 543–639,
https://doi.org/10.1017/S0962492906270016 .
Vaswani, A., N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, 2023: Attention
Is All You Need .
https://doi.org/10.48550/arXiv.1706.03762 .
榎本剛., 2021:
自己組織化マップを用いた大気循環パターンのクラスタ解析 .
京都大学防災研究所年報. B ,
64 , 313–316.
甘利俊一., 1968: パターン認識の理論.
計測と制御 ,
7 , 180–189,
https://doi.org/10.11499/sicejl1962.7.180 .
——, 2001: 自然勾配学習法-学習空間の幾何学.
計測と制御 ,
40 , 735–739,
https://doi.org/10.11499/sicejl1962.40.735 .
赤穂昭太郎, 2008: カーネル多変量解析―非線形データ解析の新しい展開 . 岩波書店,.