最小解または最大解を数値的に求める手法を数値最適化(numerical optimization)という。 変分法データ同化や機械学習では,コスト函数を最小化して最も尤もらしい解を求める。 最尤解を求めるには確率密度函数の最大値をとる解を求めても良いが、通常は負号をつけた対数尤度が最小を取る解を求める。
例えば、Equation 1.5 に対しては、 \[
\frac{(x-\bar{x})^2}{2\sigma^2}
\] Equation 1.6 に対しては、 \[
(\mathbf{x}-\bar{\mathbf{x}})^\mathrm{T}\mathbf{S}_x^{-1}(\mathbf{x}-\bar{\mathbf{x}})
\] を最小化する。
最小解には、大域最小解と局所最小解がある。 函数が凸であれば大域最小解が求まるが、凸でない場合は一般的には局所最小解が得られる。 数値最適化手法は、勾配を用いるものと用いないものに大別される。 ここでは、効率がよい勾配を用いる手法を学ぶ。
スカラー函数の最小化
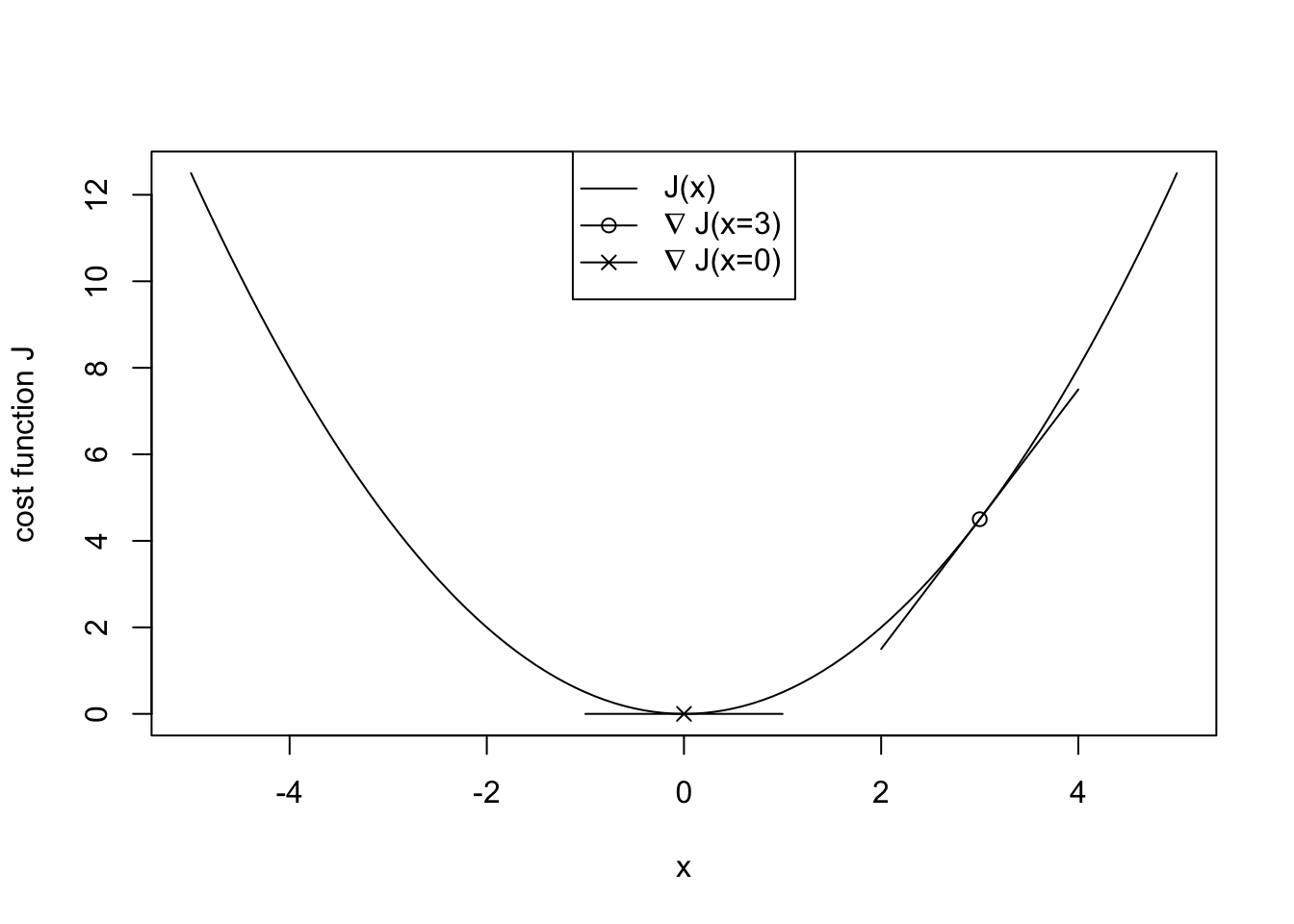
最小化の概念や用語を学ぶために、スカラーの2次函数\(J(x) = x^2/2\) を考える。 \(x=3\) において勾配は\(9/2\) で正なので、逆方向である負の方向に進めば\(J\) は小さくなる。 \(\mathrm{d}J/\mathrm{d}x = 0\) となる\(x = 0\) は、勾配が0の停留点である(1次の最適性必要条件)。 \(\mathrm{d}^2J/\mathrm{d}x^2 = 1 > 0\) なので、函数は(下に)凸(convex)であり、\(J\) は最小値である(2次の最適性十分条件)。
Code
library (latex2exp)<- function (x, xt) { xt * (x - 0.5 * xt) }<- function (x) { 0.5 * x^ 2 }curve (quadratic, - 5 , 5 , ylab = "cost function J" )curve (jac (x, 3 ), 2 , 4 , add = TRUE )curve (jac (x, 0 ), - 1 , 1 , add = TRUE )points (3 , quadratic (3 ), pch = 1 )points (0 , quadratic (0 ), pch = 4 )legend ("top" ,c (TeX (r"(J(x))" ), TeX (r"( \n abla J(x=3))" ), TeX (r"( \n abla J(x=0))" )),lty = c (1 , 1 , 1 ), pch = c (NA , 1 , 4 ))
データ同化のコスト函数
データ同化で用いる一般的なコスト函数は次のように書ける。
\[
J(\mathbf{x}) = \frac{1}{2}(\mathbf{x} - \mathbf{x}_\mathrm{f})^\mathrm{T}\mathbf{B}^{-1}(\mathbf{x} - \mathbf{x}_\mathrm{f}) + \frac{1}{2}[\mathbf{y} - H(\mathbf{x})]^\mathrm{T}\mathbf{R}^{-1}[\mathbf{y} - H(\mathbf{x})]
\tag{2.1}\]
\(\mathbf{x}\) は状態ベクトルで、最適化の対象となる制御変数(control variable)である。 \(\mathbf{x}_\mathrm{f}\) は第一推定値、\(\mathbf{y}\) は観測ベクトルを表す。 \(H\) は観測演算子(observation operator)を表し、リトーバルでは順モデル(forward model)と呼ばれる。 行列\(\mathbf{B}\) と\(\mathbf{R}\) はそれぞれ背景及び観測誤差共分散である。 右辺第1項は先験値、第2項は測定からの乖離を表し、それぞれ背景項、観測項と呼ぶ。 イノベーションが線型\(\mathbf{y} - \mathbf{H}\mathbf{x}\) の場合は2次になる。
\(\mathbf{x}\) がベクトルのとき、最適性条件を確認する。
十分条件: \(\nabla J(\mathbf{x}) = 0\) かつ\(\nabla^2 J(\mathbf{x})\) が半正定値(Section A.3 \(\mathbf{x}\) は局所最小解である。
必要条件: \(\mathbf{x}\) は局所最小解ならば、\(\nabla J(\mathbf{x}) = 0\) かつ\(\nabla^2 J(\mathbf{x})\) が半正定値でなければならない。
\(\mathbf{x}\) で微分すると、Equation 2.1 の勾配は次のように表される。
\[
\nabla J(\mathbf{x}) = \mathbf{B}^{-1}(\mathbf{x} - \mathbf{x}_\mathrm{f}) + \mathbf{H}^\mathrm{T}\mathbf{R}^{-1}(\mathbf{y} - H(\mathbf{x}))
\]
いくつかの最適化手法を概観する。 スラカー函数の最適化で2次函数は容易に最小解が求められることをみた。 そこで、ベクトル函数\(f(\mathbf{x})\) を2次近似する。 \[
f(\mathbf{x} + \mathbf{d}) \approx f(\mathbf{x}) +\mathbf{g}^\mathrm{T}\mathbf{d} + \mathbf{d}^\mathrm{T}\mathbf{G}\mathbf{d}
\tag{2.2}\] \(\mathbf{d}\) は降下ベクトル、\(\mathbf{g} = \nabla f\) 及び\(\mathbf{G} = \nabla^2 f\) は\(\mathbf{x}\) における勾配ベクトル及びへシアンである。
最急降下法
最急降下法(steepest descent)は1次までの情報、すなわち勾配を用いて降下方向を\(\mathbf{d}=-\mathbf{g}\) とする。 \[
\mathbf{x}^{(n+1)} = \mathbf{x}^{(n)} + \alpha\mathbf{d}
\] ここで\(n\) は反復回数、\(\alpha\) はステップ幅を表す。 機械学習では、最急降下法に基づくさまざまな手法が広く用いられている。
ステップ幅の計算は\(\alpha\) に対する制約付最適化問題 \[
\underset{\alpha>0}{\text{arg min}}f(\mathbf{x}^{(n)} + \alpha\mathbf{d})
\] を解くことにより得られる。 最適化におけるこの小問題は、線型探索(Section 2.8
ニュートン法
2次の情報、すなわち曲率を表すへシアンを用いるのがニュートン法である。 Equation 2.2 の停留点は連立一次方程式をなすニュートン方程式 \[
\mathbf{Gd} = -\mathbf{g}
\tag{2.3}\] \(\mathbf{x}^*\) を最小値、\(C\) を定数としたときに \[
\|\mathbf{x}^{(n+1)} - \mathbf{x}^*\| \le C\|\mathbf{x}^{(n)} - \mathbf{x}^*\|^2
\] が成り立つ。 二次函数に近ければ、少ない反復回数で収束する。
ニュートン方程式Equation 2.3 を厳密に解くと、ステップ幅は\(\alpha = 1\) となる。 ニュートン方程式は二次近似なので\(\alpha = 1\) に近く、線型探索を省略することもできる。
一方、へシアンを格納するには\(n\times n\) のメモリが必要となり計算量も\(O(n^3)\) と多いので、大規模な最適化に事実上適用できない。
ガウス・ニュートン法
函数が複数の函数の二乗和 \[
f(\mathbf{x}) = \frac{1}{2}\sum_i^k[f_k(\mathbf{x})]^2
\] で表される場合を考える。 Equation 2.1 はこれに該当する。
残差\(f_k(\mathbf{x})\) が線型及び非線型の場合を、それぞれ線型及び非線型最小二乗法問題と呼ぶ。 残差を並べたベクトルを \[
\mathbf{f} = \begin{pmatrix}f_1(\mathbf{x}) & f_2(\mathbf{x}) & \dots & f_k(\mathbf{x})\end{pmatrix}^\mathrm{T}
\] と置き、ヤコビアン \[
\mathbf{F} = \frac{\partial\mathbf{f}}{\partial{\mathbf{x}}}
\] を用いて勾配とへシアンを近似する。 \[
\mathbf{g} = \mathbf{F}^\mathrm{T}\mathbf{f}
\] \[
\mathbf{G} = \mathbf{F}^\mathrm{T}\mathbf{F}
\] ニュートン方程式Equation 2.3 の解は \[
\mathbf{d} = -\mathbf{G}^{-1}\mathbf{g} = -(\mathbf{F}^\mathrm{T}\mathbf{F})^{-1}\mathbf{F}^\mathrm{T}\mathbf{f}
\] となる。 ガウス・ニュートン法は、二次近似と整合的で、コスト函数のような(非)線型最小二乗法の定番となる解法である。
準ニュートン法
準ニュートン法は、ニュートン方程式Equation 2.3 を厳密に解かない方法である。 代表的なBFGS法Goldfarb (1970 ) は、反復の中で曲率についての情報を構築して、へシアンを明示的に計算することなく勾配で近似する。 函数評価と勾配の計算量は\(O(n^2)\) であり、へシアンの計算量\(O(n^3)\) よりも少ない。 メモリは\(O(n^2)\) 必要であるが、\(O(n)\) となる省メモリのL-BFGS法(Nocedal 1980 ; Liu and Nocedal 1989 ) も提案されている。
Nocedal and Stephen J. Wright (2006 ) に基づいて概要を説明する。
\(k+1\) 回目の反復おけるコスト函数の二次近似を \[
m_{k+1}(p) = f_{k+1} + \nabla f_{k+1}^\mathrm{T}p + \frac{1}{2}p^TB_{k+1}p
\] と表す。 コスト函数とその近似の勾配が\(x_{k+1}\) (\(p = 0\) )及び\(x_k\) (\(p = -\alpha p_k\) )で成り立つとすると、割線条件 \[
B_{k+1}s_k = y_k
\] と書ける。 ここで\(s_k = x_{k+1} - x_k\) 、\(y_k = \nabla f_{k+1} - \nabla f_k\) である。 \(B_k\) が正定値対称行列であれば曲率条件 \[
s_k^\mathrm{T} y_k >0
\] が成り立つ。 曲率条件はWolfe条件Section 2.8.4 Section 2.8.5
へシアン逆行列に対する割線条件は \[
H_{k+1} y_k = s_k
\] と書ける。 割線条件と曲率条件を満たす\(H_{k+1}\) は無数にあるので、一意に定めるために現在の\(H_k\) と近いものを選ぶと \[
H_{k+1} = V_k^\mathrm{T}H_kV_k + \rho_ks_ks_k^\mathrm{T}
\tag{2.4}\] \(V_k = I - \rho_k y_k s_k^\mathrm{T}\) 及び\(\rho_k = 1/y_k^\mathrm{T}s_k\) である。 これをBFGS公式という。 Equation 2.4 は階数2の更新である。 準ニュートン法の基本的な発想は、へシアンを一から計算せずに現在のへシアンを微修正して更新することにある。 L-BFGSは、\(H_k\) を明示的に持たずに必要なベクトルを保持するものである。
共軛勾配法
共軛勾配法(conjugate gradient, CG)は少ないメモリで効率的に数値最適化を行うことができる手法である。 ここでは、まず共軛の概念と関連する定理を示した後、互いに共軛な方向を構成する方法について述べ、共軛勾配法の計算手順を示す。
共軛(きょうやく, conjugacy)は、戦後の漢字制限の下で「共役」と書き換えられた。「きょうえき」は誤読である。 「軛」は車の轅(ながえ)の先端につけて、車を引く牛馬の後ろにかける横木を指す(スーパー大辞林)。
\(\mathbf{G}\) : 正定値対称行列、\(\mathbf{b}\) をベクトル、\(c\) をスカラーとすると、\(\mathbf{x}\) の2次函数は次のように表される。
\[
F(\mathrm{x}) = \frac{1}{2}\mathbf{x}^T\mathbf{G}\mathbf{x} + \mathbf{b}^T\mathbf{x} + c
\]
二つのベクトル\(\mathbf{u}\ne 0\) と\(\mathbf{v}\ne 0\) は以下が成り立つとき\(\mathbf{G}\) に関して共軛であると言う。 \[
\mathbf{u}^\mathrm{T}\mathbf{G}\mathbf{v} = 0
\]
幾何学的には、異なる\(\gamma\) は共通の中心を持つ楕円体の表面を表す。
\[
F(\mathrm{x}) = \gamma
\]
定理1
ベクトル\(\mathbf{d}_j\) が互いに共軛、すなわち全ての\(i\ne j\) について\(\mathbf{d}_i^T\mathbf{G}\mathbf{d}_j=0\) が成り立つならば、これらのベクトルは線型独立である。。
\(\mathbf{G}\) に関して互いに共軛な\(n\) 個の独立なベクトルの組が少なくとも1組ある-\(\mathbf{G}\) の固有ベクトルの組はそのような組を構成する。
定理2
\(\mathbf{x}_k\) と\(\mathbf{x}_{k+1}\) とを\(F(\mathbf{x})\) の最小化において、連続した二つのベクトルとする。 もし
\(\mathbf{x}_k\) が\(\mathbf{d}_l\) 方向に\(F(\mathbf{x})\) を最小化する。\(\mathbf{x}_{k+1}\) が\(\mathbf{d}_m\) 方向に\(F(\mathbf{x})\) を最小化する。\(\mathbf{d}_l\) と\(\mathbf{d}_m\) は共軛方向。
ならば\(\mathbf{x}_{k+1}\) は\(\mathbf{d}_l\) 方向にも\(F(\mathbf{x})\) を最小化する。
\(F(\mathbf{x}_k)\) の勾配を
\[
\mathbf{g}_k = \nabla F(\mathbf{x}_k)
\] と表記する。 1.と2.から\(\mathbf{g}_{k+1}\mathbf{d}_i=0\) 及び \[
\mathbf{d}_l^\mathrm{T}\mathbf{G}\mathbf{d}_m = 0
\] が\(i=0,\dots l\) のそれぞれについて成り立つことが示唆される。2次函数\(F(\mathbf{x})\) に対して\(\mathbf{g}(\mathbf{x}) = \mathbf{G}\mathbf{x} + \mathbf{b}\) なので \[
\mathbf{g}_{k+1} - \mathbf{g}_k = \mathbf{G}(\mathbf{x}_{k+1} - \mathbf{x}_k)
\] 2.から \[
\mathbf{x}_{k+1} = \mathbf{x}_k + \alpha_k\mathbf{d}_k
\] で更新を行う。ここでステップ幅\(\alpha_k\) は線型探索(1次元最小化)で求める。 \[
F(\mathbf{x}_k + \alpha_k\mathbf{d}_k) = \min_\alpha\,F(\mathbf{x}_k+\alpha\mathbf{d})
\]
定理3
\(\mathbf{d}_i,\;i=1,\dots , m\,(m \le n)\) を互いに共軛な方向とする。
\(F(\mathbf{x})\) の大域最小値は任意の初期位置\(\mathbf{x}_0\) から有限回の降下計算で求めることができる。降下計算において各\(\mathbf{d}_i\) は降下方向として1回のみ用いられる。
互いに共軛な方向の組を構成する方法
\(\mathbf{v}_0,\dots\mathbf{v}_{n-1}\) を線型独立なベクトルの組とする。 \(\mathbf{G}\) について互いに共軛(\(\mathbf{G}\) -共軛)な方向\(\mathbf{d}_0,\dots\mathbf{d}_{n-1}\) の組は以下の手順で構成できる。 \[
\mathbf{d}_0 = \mathbf{v}_0
\] とおき、連続的に \[
\mathbf{d}_i = \mathbf{v}_i + \sum_{j=0}^{i-1}a_{ij}\mathbf{d}_j
\] と定義する。
係数\(a_{ij}\) は\(\mathbf{d}_i\) がこれまでの降下方向\(\mathbf{d}_{i-1},\mathbf{d}_{i-2},\dots,\mathbf{d}_0\) に\(\mathbf{G}\) -共軛となるように\(l = 0, \dots, i-1\) に対して \[
\mathbf{d}_i^T\mathbf{G}\mathbf{d}_l = \mathbf{v}_i^T\mathbf{G}\mathbf{d}_l + \sum_{j=0}^{i-1}a_{ij}\mathbf{d}_j^T\mathbf{G}\mathbf{d}_l = 0
\] を満たすように選ぶ。 これまでの係数\(a_{ij}\) が\(\mathbf{d}_0,\dots,\mathbf{d}_{i-1}\) が\(\mathbf{G}\) -共軛になるように選ばれていれば \[
\mathbf{d}_j^T\mathbf{G}\mathbf{d}_l = 0,\;j\ne l
\] なので \[
a_{ij} = -\frac{\mathbf{v}_i^T\mathbf{G}\mathbf{d}_j}{\mathbf{d}_j^T\mathbf{G}\mathbf{d}_j},\; i=1,\dots,n-1,\;j=0,\dots,i-1
\] が得られる。 降下方向の組\(\mathbf{d}_0,\dots,\mathbf{d}_{n-1}\) は\(\mathbf{G}\) -共軛で\(\mathbf{d}_0,\dots,\mathbf{d}_{i}\) で張られた部分空間と\(\mathbf{v}_0,\dots,\mathbf{v}_{i}\) で張られた部分空間とは同一である。
共軛勾配法の計算方法
最初のステップは最急降下方向。 \[
\mathbf{v}_0 = -\mathbf{g}_0
\] 更新は \[
\mathbf{x}_1 = \mathbf{x}_0 + \alpha_0\mathbf{d}_0
\] で行い、\(\alpha_0\) は線型探索で求める。
次の降下方向は \[
\mathbf{d}_1 = -\mathbf{g}_1 + \frac{\mathbf{g}_1^T\mathbf{G}\mathbf{d}_0}{\mathbf{d}_0^T\mathbf{G}\mathbf{d}_0}\mathbf{d}_0
\] 式(6)より \[
\mathbf{g}_1 - \mathbf{g}_0 = \mathbf{G}(\mathbf{x}_1 - \mathbf{x}_0) = \alpha_0\mathbf{G}\mathbf{d}_0
\] なので(16)は\(\mathbf{G}\) を用いずに \[
\mathbf{d}_1 = -\mathbf{g}_1 + \frac{\mathbf{g}_1^T(\mathbf{g}_1 - \mathbf{g}_0)}{\mathbf{d}_0^T(\mathbf{g}_1 - \mathbf{g}_0)}\mathbf{d}_0
\] と書くことができる。
\(k+1\) 番目のステップは \[
\mathbf{d}_k = -\mathbf{g}_k + \sum_{j=0}^{k-1}\frac{\mathbf{g}_k^T\mathbf{G}\mathbf{d}_j}{\mathbf{d}_j^T\mathbf{G}\mathbf{d}_j}\mathbf{d}_j
\] または \[
\mathbf{d}_k = -\mathbf{g}_k + \sum_{j=0}^{k-1}\frac{\mathbf{g}_k^T(\mathbf{g}_{j+1} - \mathbf{g}_j)}{\mathbf{d}_j^T(\mathbf{g}_{j+1} - \mathbf{g}_j)}\mathbf{d}_j
\tag{2.5}\]
\(\mathbf{d}_0,\dots,\mathbf{d}_{k-1}\) で張られた部分空間と\(\mathbf{v}_0,\dots,\mathbf{v}_{k-1}\) で張られた部分空間とは同一なので、3.より \[
\mathbf{g}_k^T\mathbf{d}_j = 0\;j=0,\dots,k-1
\] 及び \[
\mathbf{g}_k^T\mathbf{g}_j = 0\;j=0,\dots,k-1
\] となることを利用すれば(Equation 2.5 )を簡単にすることができる。 \[
\mathbf{d}_k = -\mathbf{g}_k + \beta_k\mathbf{d}_{k-1}
\] ここで \[
\beta_k = \frac{\mathbf{g}_k^T(\mathbf{g}_k - \mathbf{g}_{k-1})}{\mathbf{d}_{k-1}^T(\mathbf{g}_k - \mathbf{g}_{k-1})}
\]
\[
\mathbf{g}_k^T\mathbf{g}_j = \mathbf{g}_k^T\mathbf{d}_j = 0,\; j = 0,\dots,k-1
\] \[
\mathbf{d}_{k-1} = -\mathbf{g}_{k-1} + \beta_{k-1}\mathbf{d}_{k-2}
\] を用いると \[
\beta_k = \frac{\mathbf{g}_k^T(\mathbf{g}_k - \mathbf{g}_{k-1})}{\mathbf{g}_{k-1}^T\mathbf{g}_{k-1}} = \frac{\mathbf{g}_k^T\mathbf{g}_k}{\mathbf{g}_{k-1}^T\mathbf{g}_{k-1}}
\]
最小化の過程で降下方向\(\mathbf{d}_k\) を選択するには、現在と一つ前の勾配\(\mathbf{g}_k\) と\(\mathbf{g}_{k-1}\) 及び一つ前の降下方向\(\mathbf{d}_{k-1}\) の三つのベクトルだけが分かれば良い。\(n\) が大きいときに効果的。
\(n\) 次元の2次函数は最大\(n\) 回で収束する。
Polak–Ribiereアルゴリズム
\[
\beta_k = \frac{\mathbf{g}_{k+1}^T(\mathbf{g}_{k+1} - \mathbf{g}_{k})}{\mathbf{g}_{k}^T\mathbf{g}_{k}}
\] とする。
2次函数では\(\mathbf{g}_{k+1}\mathbf{g}_k=0\) なのでFletcher–Reevesアルゴリズムに一致する。 非線型性や非厳密線型探索が原因で共軛性が失われると、最適化が停滞する。 このとき\(\mathbf{d}_k\) は\(\mathbf{g}_k\) とほぼ直交する。 \[
\mathbf{g}(\mathbf{x}_{k+1})=\nabla F(\mathbf{x}_{k+1}) \approx \nabla F(\mathbf{x}_k) = \mathbf{g}_k
\] Polak–Ribiereアルゴリズムの\(\beta_{k+1}\) は0に近くなり最急降下方向に向くことで停滞を打破する。
線型探索
線型探索では,探索方向\(p_k\) に進む幅\(\alpha_k\) を求める。 反復は次の式で与えられる。
\[
x_{k+1} = x_{k} + \alpha_k p_k
\]
探索方向\(p_k\) は通常降下方向にとる。 \(p_k^T \nabla f_k < 0\)
ステップ幅
線型探索では,\(x_k\) や\(p_k\) を固定し,最適化の対象を\(\alpha\) に関する1変数函数と見る。
\[
\phi(\alpha) = f(x_k + \alpha_k p_k),\;\alpha > 0
\]
最小を厳密に求めるには,多数の函数評価が必要となる。
なるべく計算コストをかけずに,ある程度\(f\) が減少するような厳密ではない線型探索を行う。
Armijo条件
十分な減少するように\(\alpha\) を選択する。
\[
f(x_k + \alpha_k p_k) \le f(x_k) + c_1\alpha_k\nabla f_k^T p_k
\]
左辺は線型探索の対象とする\(\phi(\alpha_k)\)
右辺は\(\alpha_k\) の1次函数\(l(\alpha_k)\) で,傾き\(c_1\alpha\nabla f_k^T p_k\) は負
減少量はステップ幅\(\alpha_k\) 及び方向微分\(\nabla f_k^T p_k\) に比例
\(c_1 \in (0, 1)\) で通常\(c_1 = 10^{-4}\) のような非常に小さい値を用いる。
曲率条件
十分な減少だけでは,ステップ幅が極端に短くなり,最適化が進まないことがある。 極端に短いステップ幅を除くために二つ目の条件として曲率条件を与える。
\[
\nabla f(x_k + \alpha_k p_k)^T p_k \ge c_2\nabla f_k^Tp_k
\]
左辺\(\phi'(\alpha)\) が右辺\(\phi'(0)\) の\(c_2\) 倍以上であるとする条件
\(\phi'(\alpha_k)\) が大きな負なら,ステップ幅を大きくとったほうが良い。あまり大きくない負か正ならこれ以上この方向に進む必要はないので探索を打ち切る。
\(c_2 \in (c_1, 1)\) でニュートン法や準ニュートン法では0.9,共軛勾配法では0.1が用いられることが多い。
Wolfe条件
十分な減少と曲率条件を合わせて、Wolfe条件と呼ぶ。 \[
\begin{aligned}
f(x_k + \alpha_k p_k) &\le f(x_k) + c_1\alpha_k\nabla f_k^T p_k\\
\nabla f(x_k + \alpha_k p_k)^T p_k &\ge c_2\nabla f_k^Tp_k
\end{aligned}
\] ここで\(0 < c_1 < c_2 < 1\) である。
強Wolfe条件
Wolfe条件は最小から離れた点ならどこでも満たされうる。 そこで以下の制約を設け、強Wolfe条件と呼ぶ。
\(\phi'(\alpha_k)\) が大きな正にならないように制約最小や極小,停留点のから遠いところを排除
\[
\begin{aligned}
f(x_k + \alpha_k p_k) &\le f(x_k) + c_1\alpha_k\nabla f_k^T p_k\\
|\nabla f(x_k + \alpha_k p_k)^T p_k| &\le c_2|\nabla f_k^Tp_k|
\end{aligned}
\]
以下の条件のときWolfe条件,強Wolfe条件が満たすステップ幅\(\alpha_k\) の区間が存在する。
\(f\) が連続微分可能\(f\) は下に有界\(0 < c_1 < c_2 < 1\) \(p_k\) が降下方向
Broyden, C. G., 1970: The convergence of a class of double-rank minimization algorithms 1.
General considerations.
IMA J. Appl. Math. ,
6 , 76–90,
https://doi.org/10.1093/imamat/6.1.76 .
Fletcher, R., 1970: A new approach to variable metric algorithms.
The Computer Journal ,
13 , 317–322,
https://doi.org/10.1093/comjnl/13.3.317 .
Goldfarb, D., 1970: A family of variable-metric methods derived by variational means.
Math. Comput. ,
24 , 23–26,
https://doi.org/10.1090/S0025-5718-1970-0258249-6 .
Liu, D. C., and J. Nocedal, 1989: On the limited memory
BFGS method for large scale optimization.
Math. Programming ,
45 , 503–528,
https://doi.org/10.1007/BF01589116 .
Nocedal, J., 1980: Updating quasi-
Newton matrices with limited storage.
Math. Comput. ,
35 , 773–782,
https://doi.org/10.2307/2006193 .
——, and Stephen J. Wright, 2006: Numerical Optimization . 2nd ed. Springer,.
Shanno, D. F., 1970: Conditioning of quasi-
Newton methods for function minimization.
Math. Comput. ,
24 , 647–656,
https://doi.org/10.1090/S0025-5718-1970-0274029-X .